🎄数据结构java实现
🍭重要属性
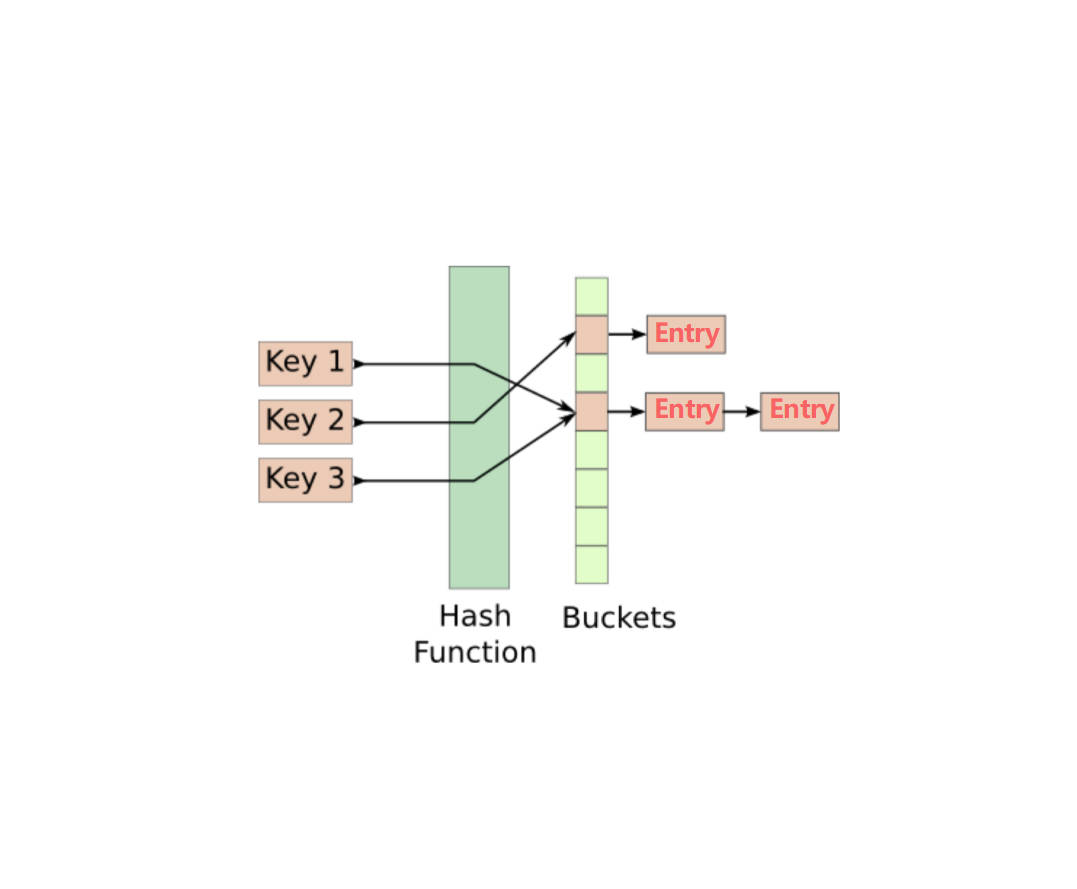
哈希表中的元素存储在Entry中 首先来定义Entry
/**
@author Liu Xianmeng
@createTime 2023/8/5 15:01
@instruction 模拟 HashTable 类
*/
public class HashTable {
/**
* 条目类
*
* 哈希表中实际存储的value在Entry对象中 每个Entry对象有一个hash哈希码属性
* 除此之外还有重要key和value 以及next属性(哈希数组一旦发生冲突 就需要扩充链表)
*/
static class Entry {
int hash; // 哈希码
Object key; // 键
Object value; // 值
Entry next; // next指向下一个条目 -> 数组引向的链表
// 只有计算出传进来的key的hash值后才能新建一个Entry对象
public Entry(int hash, Object key, Object value) {
this.hash = hash;
this.key = key;
this.value = value;
}
}
}
除了Entry类对象属性之外 还有以下重要的属性
public class HashTable {
static class Entry {...}
// 哈希table的桶数组
private Entry[] table = new Entry[16];
// 哈希table实际已经存储的元素的个数
private int size = 0;
// 加载因子 -> 扩容因子
private float loadFactor = 0.75f;
// 扩容界限值 -> 如果数组桶被占用的个数超过这个threshold值 HashTable就会进行扩容
private int threshold = (int) (loadFactor * table.length);
}
🍭hash()函数
增删改查的第一步就是获取哈希值 所以先例实现hash()函数
哈希函数是一种将任意长度的输入数据转换成固定长度输出的算法,它通常用于数据的加密、索引或验证等应用中。开发者根据具体的需求和应用场景,选择合适的哈希函数并进行实现。
哈希函数需要具备以下几个特性:首先,相同的输入始终会生成相同的输出;其次,不同的输入能够生成不同的输出;第三,输出的长度是固定的;最后,对于给定的输出,很难通过逆向运算得到原始的输入。
/**
* 这个函数用于计算对象的哈希值 它接收一个参数key 返回一个int类型的哈希值
* @param key
* @return
*/
private static int hash(Object key) {
/**
* 首先 通过判断key是否为String类型来选择不同的哈希算法
* 如果key是String类型 使用MurMur3算法进行哈希计算
* 该算法使用UTF-8字符集将字符串转换为字节数组 并返回32位的哈希值
*/
if (key instanceof String) {
return Hashing.murmur3_32().hashString((CharSequence) key, StandardCharsets.UTF_8).asInt();
}
/**
* 如果key不是String类型 就调用对象的hashCode()方法获取默认的哈希值
* 然后通过对哈希值进行位移操作(hash >>> 16)和异或运算(hash ^)来增加哈希的随机性和分布性
*
* 最终 返回计算得到的哈希值作为函数的结果
* 这种哈希函数可以尽量减少哈希冲突 以提高哈希表等数据结构的性能和效率
*/
int hash = key.hashCode();
return hash ^ (hash >>> 16);
}
🍭resize()扩容函数
接下来就是HashTable的resize函数实现了 它需要完成哈希表重构的任务 将每个桶中的所有元素按照指定的算法分为两组 第一组还是在原先的位置 第二组放置在新开辟的桶等距table.length的位置
/**
* 完成HashTable的扩容任务
*/
private synchronized void resize() {
// 创建一个新的Entry数组 作为扩容后的HashTable 容量为先前的2倍
Entry[] newTable = new Entry[table.length << 1];
/**
* 接下来遍历🍭原桶数组的每一个Entry对象进行处理
* 注意是遍历原桶数组
*/
for (int i = 0; i < table.length; i++) {
// 拿到每个链表头
Entry p = table[i];
if (p != null) {
/*
拆分链表,移动到新数组,拆分规律
* 一个链表最多拆成两个
* hash & table.length == 0 的一组
* hash & table.length != 0 的一组
p
0->8->16->24->32->40->48->null
a
0->16->32->48->null
b
8->24->40->null
*/
Entry aRear = null;
Entry bRear = null;
Entry aHead = null;
Entry bHead = null;
while (p != null) {
// 分配到 a
if ((p.hash & table.length) == 0) {
if(aHead == null){
aHead = p;
aRear = p;
} else {
aRear.next = p;
aRear = aRear.next;
}
}
// 分配到 b
else {
if(bHead == null) {
bHead = p;
bRear = p;
} else {
bRear.next = p;
bRear = bRear.next;
}
}
p = p.next;
}
// 规律: a链表保持索引位置不变 b 链表索引位置 + table.length
if (aRear != null) {
aRear.next = null;
newTable[i] = aHead;
}
if (bRear != null) {
bRear.next = null;
newTable[i + table.length] = bHead;
}
}
}
// 更新扩容后的table
table = newTable;
// 更新扩容阈值
threshold = (int) (loadFactor * table.length);
}
🍭put()函数
put函数会使用到hash函数和resize函数 第一个put函数是我们最长使用到的 它只有两个参数
/**
* 往Hash表添加元素
* @param key
* @param value
*/
public synchronized void put(Object key, Object value) {
// 首先计算这个key的hash值
int hash = hash(key);
// 然后根据hash值来存放元素
put(hash, key, value);
}
第二个put函数则是真正put数据的函数 计算idx下标的方法是等价于取余运算的 但是采用下面的方式会使得运算效率更高
/**
* 根据hash值往Hash表添加元素
* @param key
* @param value
*/
void put(int hash, Object key, Object value) {
/**
* 计算存储桶下标 等价于取模运算 但是比取模运算的效率更高
*
* 将table.length - 1用作位运算的掩码 是为了确保计算出的索引值在有效范围内
* 这是因为table.length通常是一个2的幂,例如16、32、64等,而使用位运算的效率比较高
* 当减1后,我们可以得到一个全为1的二进制值
*
* 通过hash & (table.length - 1) 可以将hash的二进制值与全为1的掩码进行位与运算
* 这相当于只保留hash的低位部分(即只取hash的后几位),忽略了高位部分
* 由于二进制掩码全为1,运算结果在0到table.length-1之间变化,刚好对应哈希表的索引范围
*
* 这样做的好处是,无论hash的值有多大,最终计算出的索引值都在合理的范围内
* 使得元素能够平均地分散到哈希表的不同槽位中,减少冲突的可能性
* 同时,这种操作也相当于对hash值进行了取模运算,但是位运算比取模运算更加高效
*/
int idx = hash & (table.length - 1);
/**
* 根据当前的桶的位置是否为空来执行不同的操作
*/
if (table[idx] == null) {
// 1. idx 处有空位, 直接新增
table[idx] = new Entry(hash, key, value);
} else {
// 2. idx 处无空位, 沿链表查找 有重复key更新,否则新增
Entry p = table[idx];
// 持续查找要put的元素是否已经存在
while (true) {
/**
* 如果遇到相同的key则更新value即可 更新后put操作就完成了 直接返回
*/
if (p.key.equals(key)) { // 注意这个地方并没有用hash值去作比较 而是用equals方法作比较
p.value = value; // 更新
return;
}
/**
* 如果找到链表的尾部都没找到 则退出查找新增元素 并挂在链表的尾部
*/
if (p.next == null) {
break;
}
// 循环查找
p = p.next;
}
// 新增
p.next = new Entry(hash, key, value);
}
// 新增元素后size++
size++;
// 如果size超过了阈值则进行扩容
if (size > threshold) resize();
}
🍭get()函数
有了前面的put函数的铺垫 get函数的实现就轻松一些了 很容易理解
/**
* 根据key获取元素
* @param key
* @return
*/
public synchronized Object get(Object key) {
int hash = hash(key);
return get(hash, key);
}
/**
* 根据 hash 码获取 value
* @param hash
* @param key
* @return
*/
Object get(int hash, Object key) {
// 对hash值取余
int idx = hash & (table.length - 1);
if (table[idx] == null) {
return null;
}
Entry p = table[idx];
// 循环查找 找不到返回null
while (p != null) {
if (p.key.equals(key)) {
return p.value;
}
p = p.next;
}
return null;
}
🍭remove函数
删除元素的时候要注意所删除的元素是否存在 以及要删除的元素是不是链表头
/**
* 根据 hash 码删除,返回删除的 value
* @param hash
* @param key
* @return
*/
Object remove(int hash, Object key) {
int idx = hash & (table.length - 1);
if (table[idx] == null) {
return null;
}
Entry p = table[idx];
// 借助prev结点来删除目标结点
Entry prev = null;
while (p != null) {
if (p.key.equals(key)) {
// 找到了, 删除
if (prev == null) {
/**
* 如果prev为null 说明要删除的元素是链表头
* 直接把table[idx]赋值为next即可
*/
table[idx] = p.next;
} else {
// 删除目标非链表头
prev.next = p.next;
}
size--;
return p.value;
}
// 没找到则更新prev
prev = p;
p = p.next;
}
// while循环没找到则说明要删除的元素不存在 返回null
return null;
}
/**
* 根据key删除元素
* @param key
* @return
*/
public synchronized Object remove(Object key) {
int hash = hash(key);
return remove(hash, key);
}
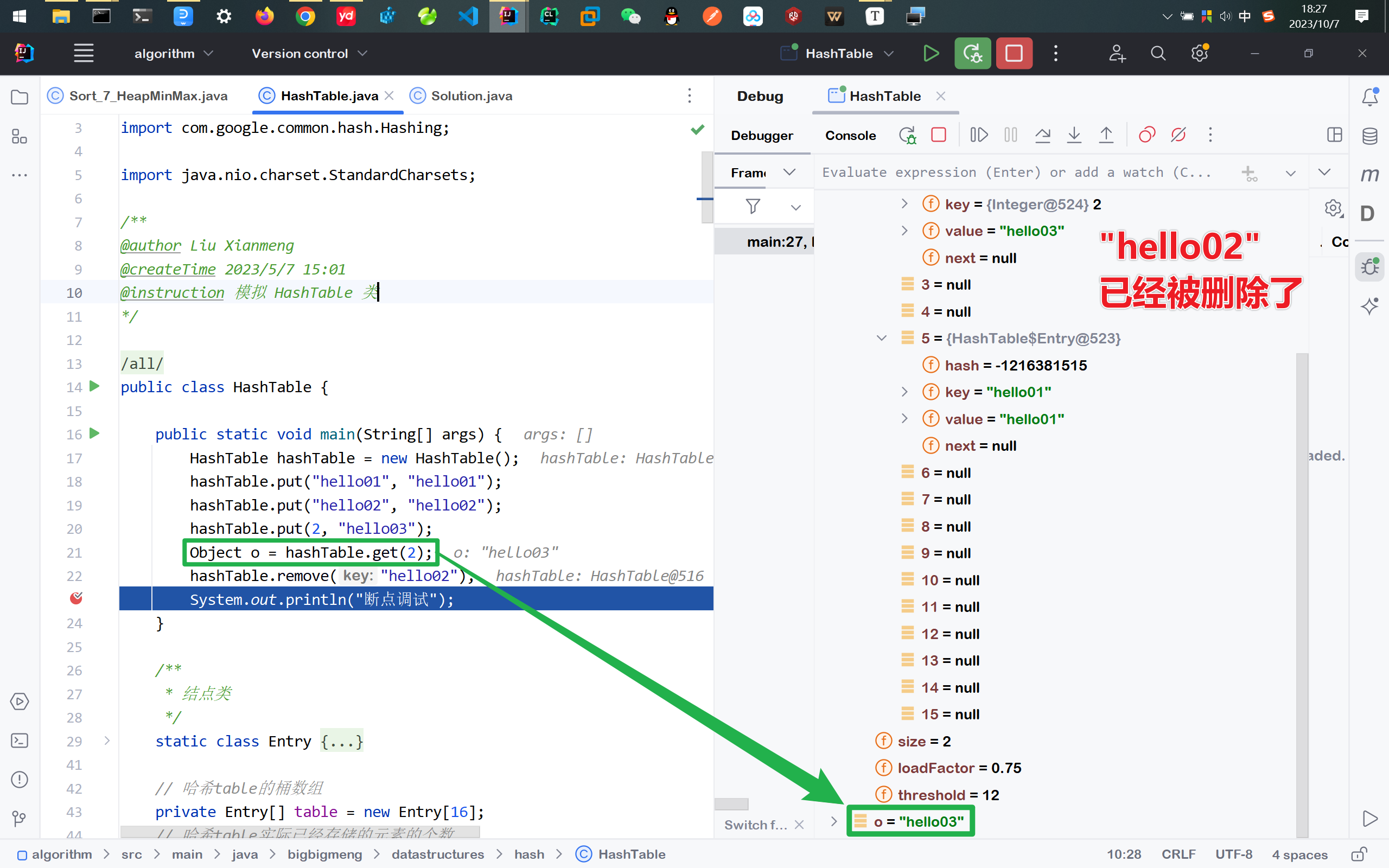
⚡执行测试
public static void main(String[] args) {
HashTable hashTable = new HashTable();
hashTable.put("hello01", "hello01");
hashTable.put("hello02", "hello02");
hashTable.put(2, "hello03");
Object o = hashTable.get(2);
hashTable.remove("hello02");
System.out.println("断点调试");
}
测试结果如下