
告警概述
在Prometheus和Grafana的监控系统中,报警(Alerting)信息的展示通常是通过配置Prometheus来实现的,而Grafana用于可视化这些报警信息。在Prometheus监控体系中,Alertmanager是一个专门用于处理报警的组件,而Grafana可以用来可视化这些报警信息。以下是它们之间的关系和工作流程:
- Prometheus生成报警: Prometheus根据配置的报警规则(在Prometheus配置文件中的
rule_files部分定义)来评估时间序列数据。当规则条件满足时,Prometheus会生成报警。 - Prometheus发送报警到Alertmanager: 一旦生成报警,Prometheus会将这些报警发送到配置好的Alertmanager实例。Prometheus配置文件中的
alerting部分定义了Alertmanager的地址。 - Alertmanager处理报警: Alertmanager接收来自Prometheus的报警,并根据其配置文件(通常是
alertmanager.yml)来处理这些报警。它可以对报警进行去重、分组、路由、抑制等操作,并将处理后的报警发送到不同的通知渠道,如邮件、Slack、Webhook等。 - c: Grafana可以通过连接到Alertmanager来获取报警信息。在Grafana中,你可以添加Alertmanager作为数据源,然后使用Grafana的UI来查看当前的报警状态。
- Grafana展示报警信息: 在Grafana中,你可以创建仪表板并添加报警列表面板,展示从Alertmanager获取的报警信息。这样,用户就可以直观地看到当前的报警状态,以及报警的历史记录。
- Grafana的通知功能: Grafana本身也支持配置通知渠道,可以直接从Grafana发送报警通知,但这通常需要额外的配置,并且与Alertmanager的通知功能有所重叠。
设置并配置Alertmanager
DEMO_START
拉取Alertmanager Docker镜像:
docker pull prom/alertmanager
运行Alertmanager容器: 暴露Alertmanager的端口(默认是9093):
docker run -d -p 9093:9093 --name alertmanager prom/alertmanager
#备份命令(后面会用到)
docker run -d -p 9093:9093
-v /export/server/PROMETHEUS-SUM-20240905/alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml
--name alertmanager prom/alertmanager
--config.file=/etc/alertmanager/alertmanager.yml
--storage.path=/export/server/PROMETHEUS-SUM-20240905/alertmanager
#备份命令注释
- `-d` 表示以守护进程模式运行容器。
- `-p 9093:9093` 将容器的9093端口映射到宿主机的9093端口。
- `-v /path/to/alertmanager.yml:/etc/alertmanager/alertmanager.yml` 将宿主机上的Alertmanager配置文件挂载到容器中。
- `--name alertmanager` 为容器指定一个名称。
- `--config.file=/etc/alertmanager/alertmanager.yml` 指定Alertmanager的配置文件路径。
- `--storage.path=/alertmanager` 指定Alertmanager存储数据的路径。
进入容器
docker exec -it 4ab1 /bin/sh
查看目录结构: 一旦你进入了容器,就可以使用Linux命令来查看目录结构,例如:
ls /etc/alertmanager

或者查看整个文件系统的结构:
ls /

查看Alertmanager配置文件: Alertmanager的默认配置文件通常位于 /etc/alertmanager 目录下。你可以使用以下命令查看配置文件:
cat /etc/alertmanager/alertmanager.yml
配置Alertmanager:以下是一个简单的配置文件示例:
global:
smtp_smarthost: 'smtp.example.com:25'
smtp_from: 'alertmanager@example.com'
smtp_auth_username: 'alertmanager'
smtp_auth_password: 'password'
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: 'default'
routes:
- match:
alertname: HighRequestLatency
receiver: 'team-X-mails'
receivers:
- name: 'default'
email_configs:
- to: 'oncall@example.com'
- name: 'team-X-mails'
email_configs:
- to: 'team-X@example.com'
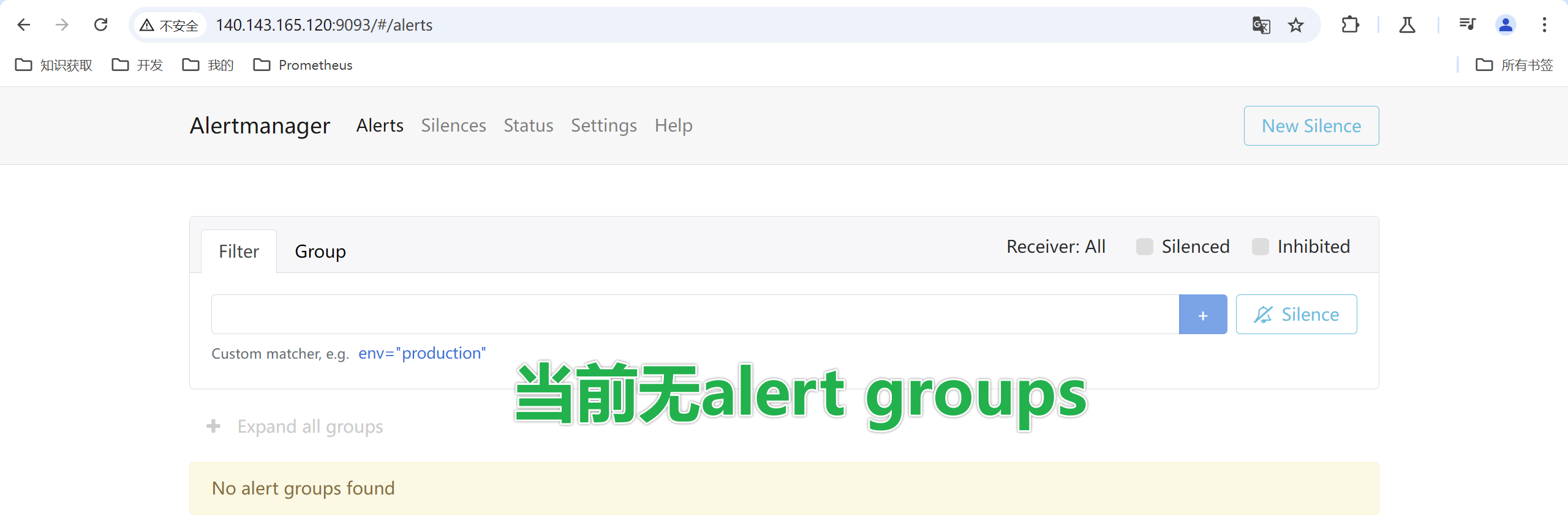
验证Alertmanager: 启动容器后,你可以通过访问http://IP:9093来验证Alertmanager是否正常运行。
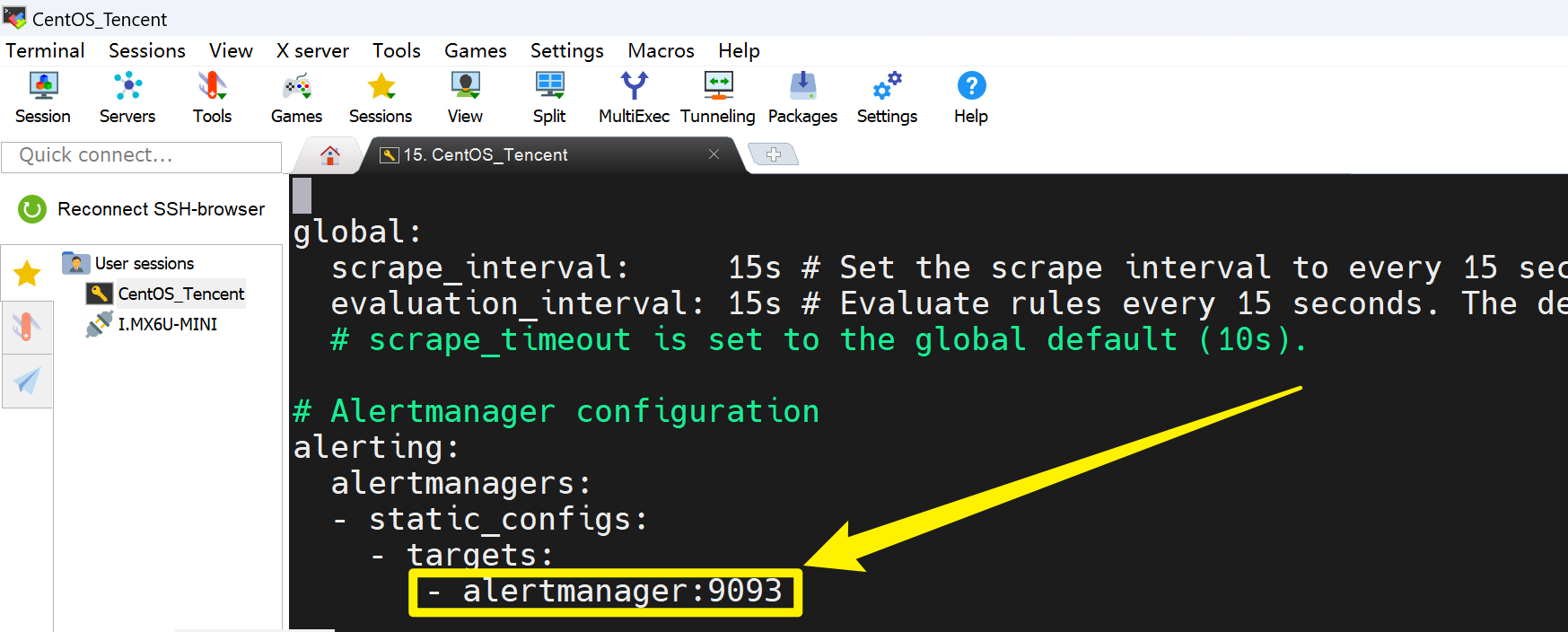
集成到Prometheus: 最后,你需要在Prometheus的配置文件prometheus.yml中指定Alertmanager的地址,以便Prometheus可以将报警发送给Alertmanager:
alerting:
alertmanagers:
- static_configs:
- targets:
- 'localhost:9093'
重启Prometheus: 修改配置后,重启Prometheus服务以使新的配置生效。
./start-prometheus.sh
给Prometheus添加一个告警规则
创建新文件vi first-rule.yml
groups:
- name: example
rules:
- alert: HighRequestLatency
expr: job:request_latency_seconds:mean5m{job="myjob"} > 0.5
for: 1m
labels:
severity: page
annotations:
summary: "High request latency (instance {{ $labels.instance }})"
description: "The average request latency is more than 0.5 seconds."
配置prometheus.yml文件:
rule_files:
- "first-rule.yml"
重启Prometheus: 修改配置后,重启Prometheus服务以使新的配置生效。
./start-prometheus.sh