
🎄说明
本文所用的演示项目为 Java工程师 Apache Dubbo 3 🌱第一个入门案例 所用的代码
🎄Dubbo高级特性 -> 序列化
🍭概述
在JavaSE的序列化基础知识中,我们已经知道,Java对象序列化是指将Java对象转换为字节流的过程,以便可以将其保存到文件、传输到网络上,或者以其他方式进行持久化存储。Java对象序列化的意义包括以下几点:
数据持久化:将对象的状态保存到文件中实现数据持久化。当程序退出后,这些对象可以被
通过读取文件反序列化恢复,从而确保数据不会丢失。网络传输:通过对象序列化,可以将对象转换为字节流,
在网络上传输。这在分布式系统和客户端-服务器之间的通信中非常有用,可以方便地在不同的系统之间传递复杂的对象。进程间通信:对象序列化也为不同进程之间的通信提供了方便,例如在Java RMI(远程方法调用)中,通过对象序列化可以将对象在不同的Java虚拟机之间进行传输。
对象克隆:通过对象序列化和反序列化,
可以实现对象的深度克隆,即产生一个与原始对象完全相同的新对象,而不是简单的引用复制。
Dubbo的内部已经将序列化和反序列化内部封装了,我们在使用Dubbo的时候,只需要把pojo类实现Serializable接口 并且把👻pojo模块单独作为分布式系统中的一个模块进行使用
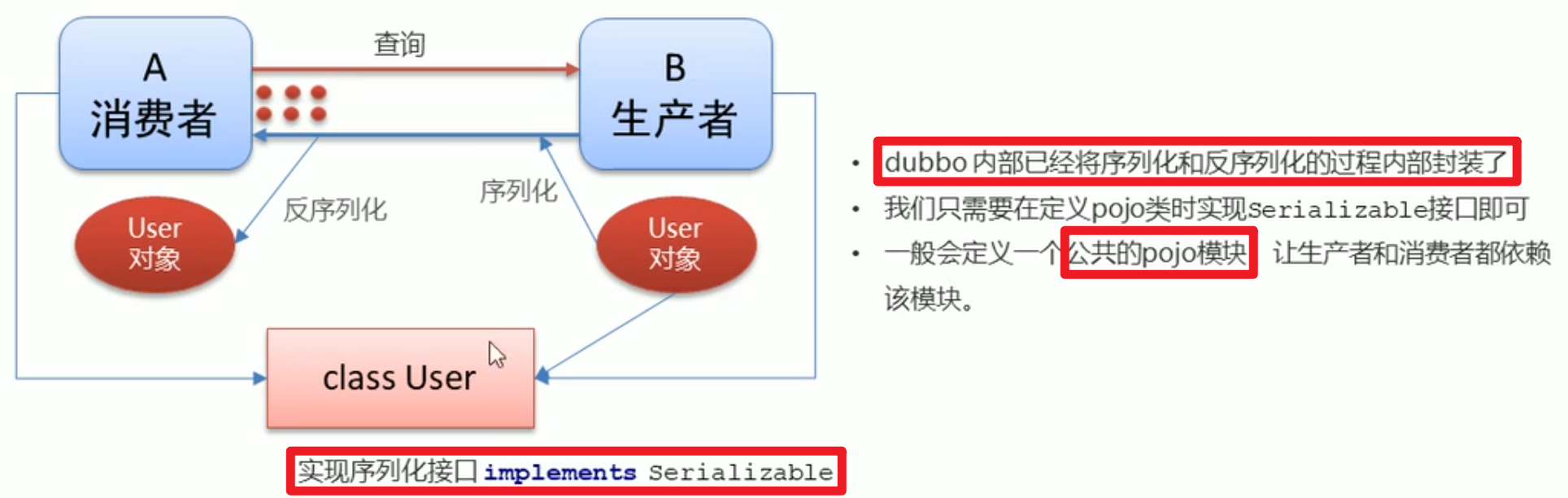
❓❓分布式项目的pojo模块必须要实现Serializable接口吗
这取决于pojo类的具体使用场景
(1)如果分布式系统涉及到将POJO对象进行序列化(例如在网络传输中或将对象保存到缓存或数据库中),那么让POJO模块实现Serializable接口通常是一个良好的做法,因为这样可以确保对象在不同 JVM 之间进行传输时能够被正确序列化和反序列化。
(2)如果你的POJO对象仅在单个 JVM 实例内部使用,并不涉及网络传输或持久化操作,那么并不一定需要强制实现Serializable接口
🍭举例使用
注意 将来所有的pojo对象都需要实现序列化接口
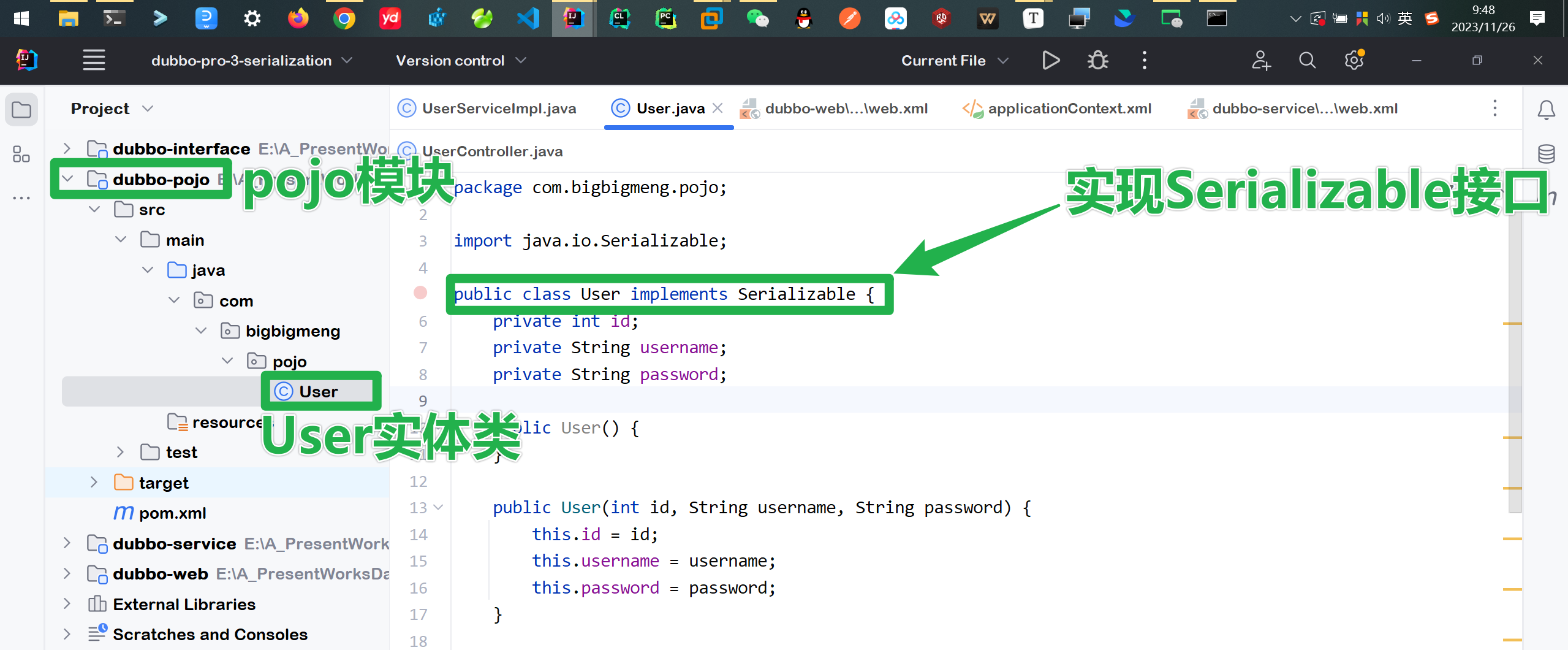
❓❓不实现序列化接口会怎么样?
把序列化接口取消 启动项目进行访问 看看会发生什么
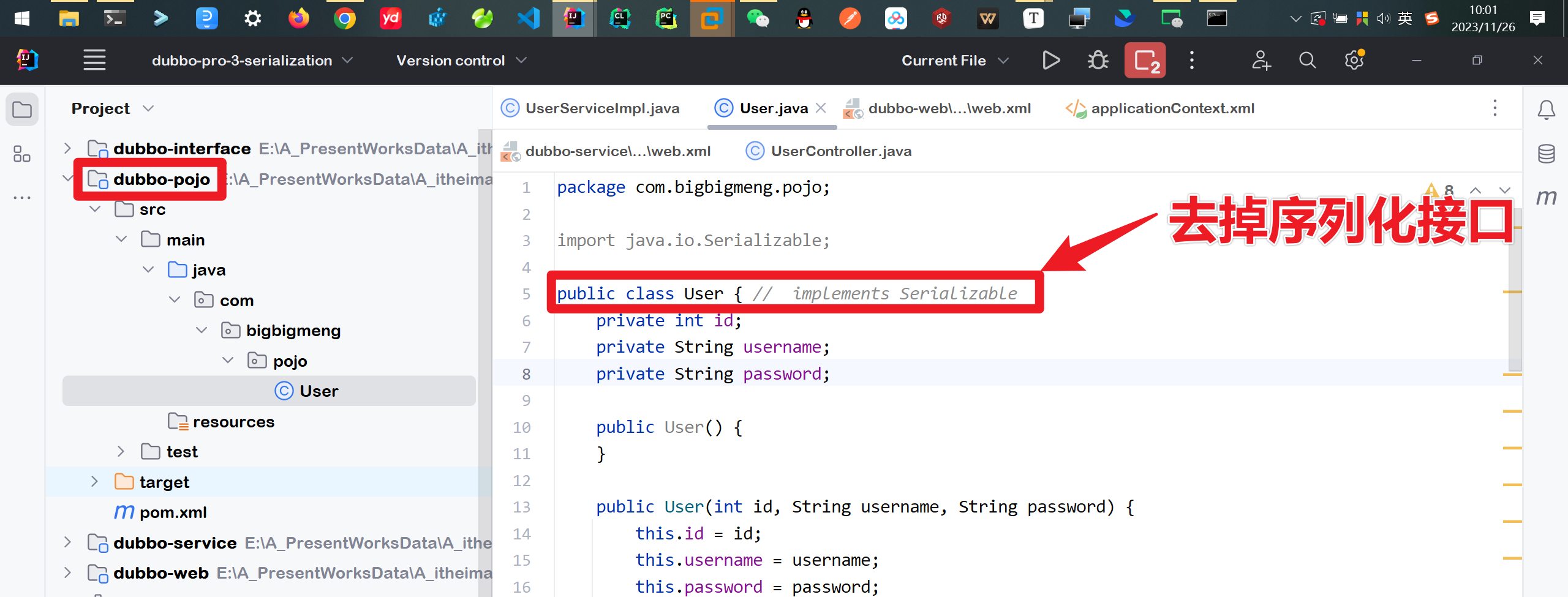
现在来看依然能够正常访问 这是因为项目目前没有涉及到pojo对象的传输 之后可以再次进行验证

🎄Dubbo高级特性 -> 地址缓存
🍭问题引出
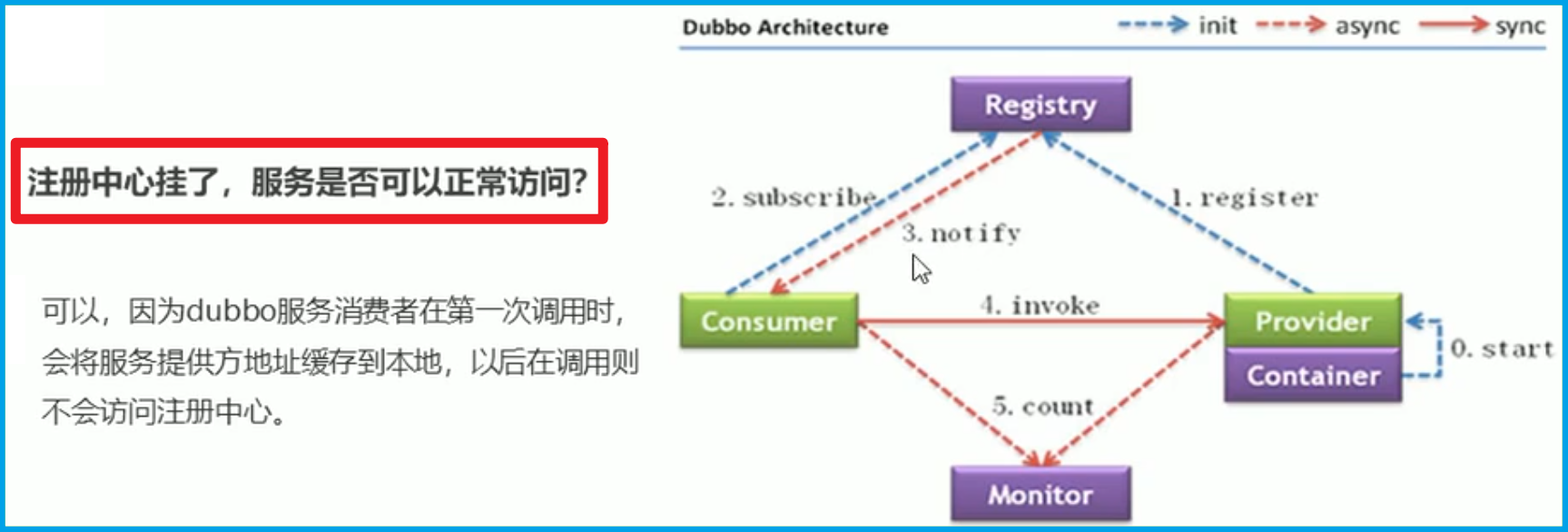
注册中心宕机服务是否还能正常访问?答案是
可以因为Dubbo服务消费者在第一次调用服务提供方提供的服务时 会将服务提供方的地址缓存到本地 以后在调用的时候则不会访问注册中心🟥但是如果想要注册新的服务 就需要🟩
修复注册中心修复好才能注册新的服务
🎄Dubbo高级特性 -> 超时和重试
🍭可能出现的问题
(1)当服务消费者调用服务提供者的时候发生了阻塞 这个时候,服务消费者会一直等待下去
(2)在某个峰值时刻 大量的请求可能会同时请求服务消费者 这样会造成🔴
线程大量堆积形成雪崩
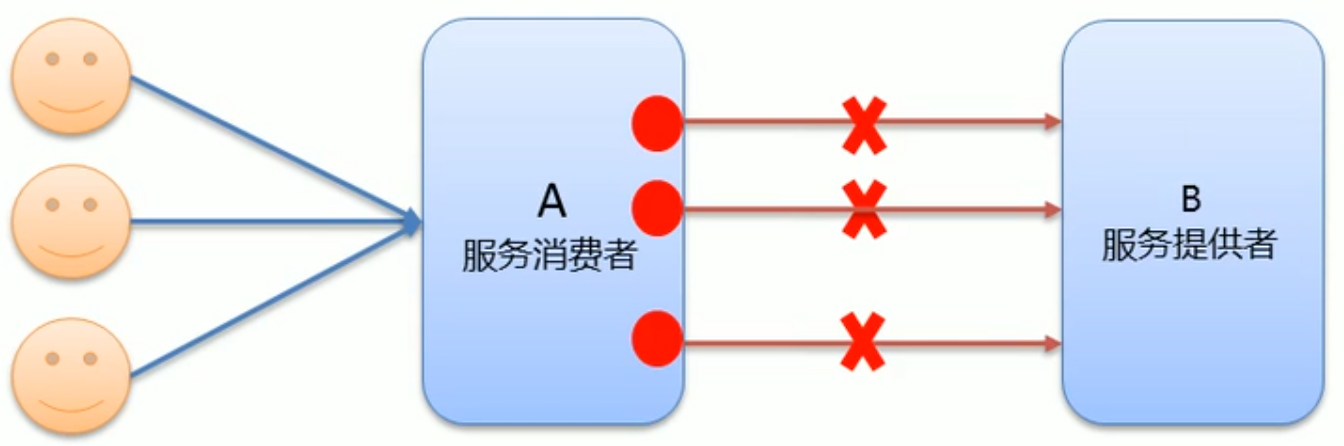
🍭针对此问题Dubbo的解决方案
Dubbo利用超时机制来解决这个问题 设置一个超时时间 如果在这个时间段内 无法完成服务的访问 则自动断开连接 从而
避免请求线程的堆积和其引发的进一步问题
🍭实践操作
超时重试的配置在服务提供方和服务消费方都可以进行配置 服务提供方使用@Service注解进行配置 服务消费方使用@Reference注解进行配置
一般来说超时时间配置在服务的提供方也就是✅在@Service注解上进行配置
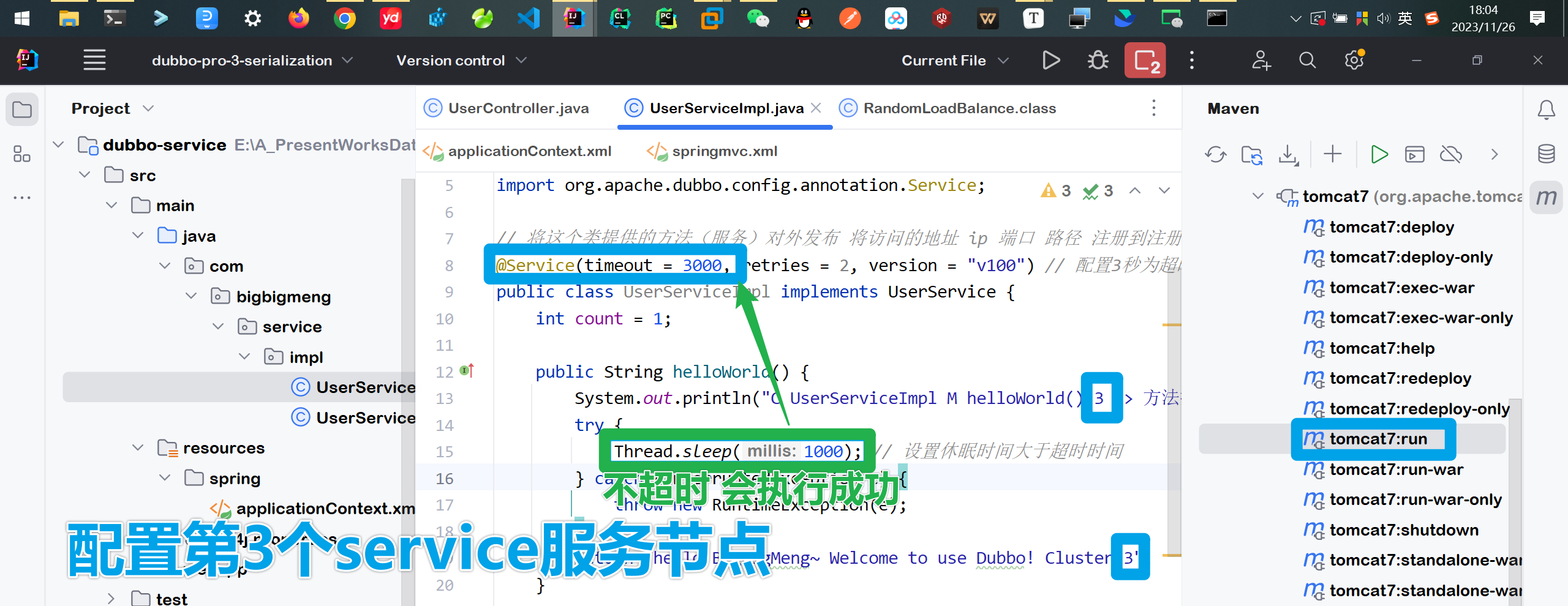
演示@Service注解上进行配置超时
先配置service模块的服务提供类
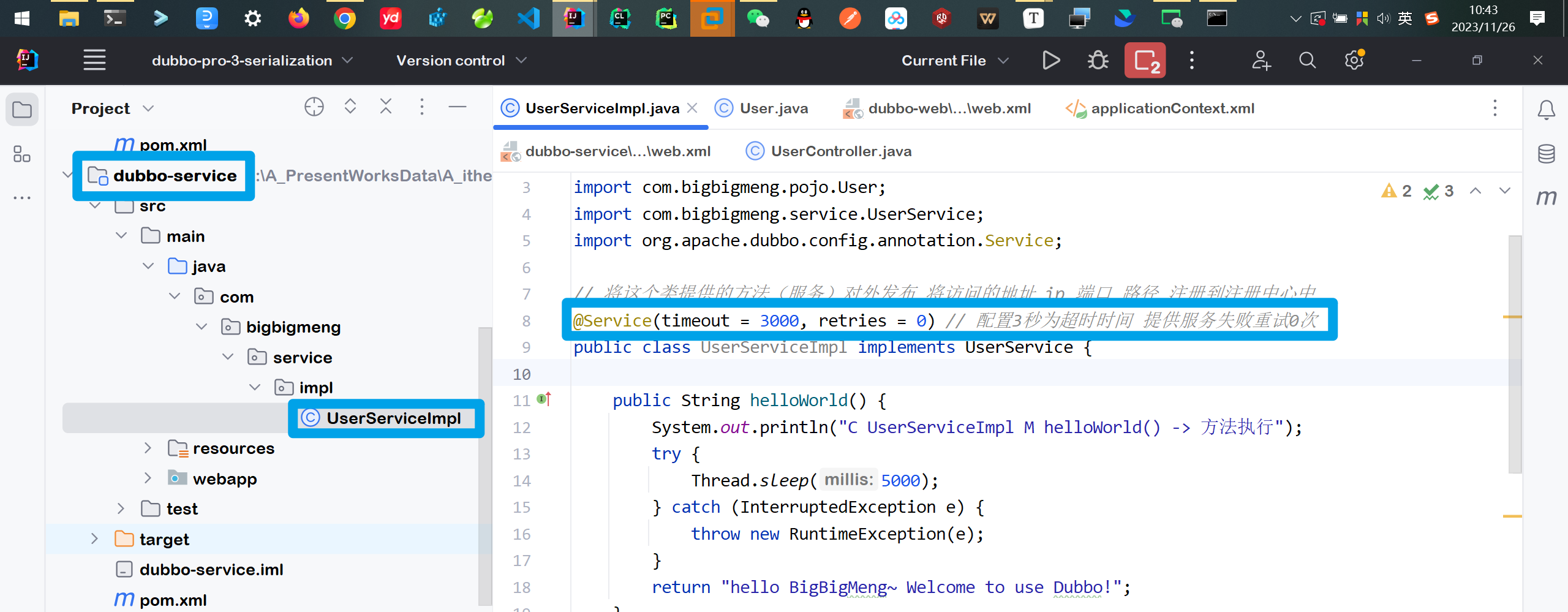
package com.bigbigmeng.service.impl;
import org.apache.dubbo.config.annotation.Service; // 🎯@Service注解
@Service(timeout = 3000, retries = 0) // 🎯配置3秒为超时时间 提供服务失败重试0次
public class UserServiceImpl implements UserService {
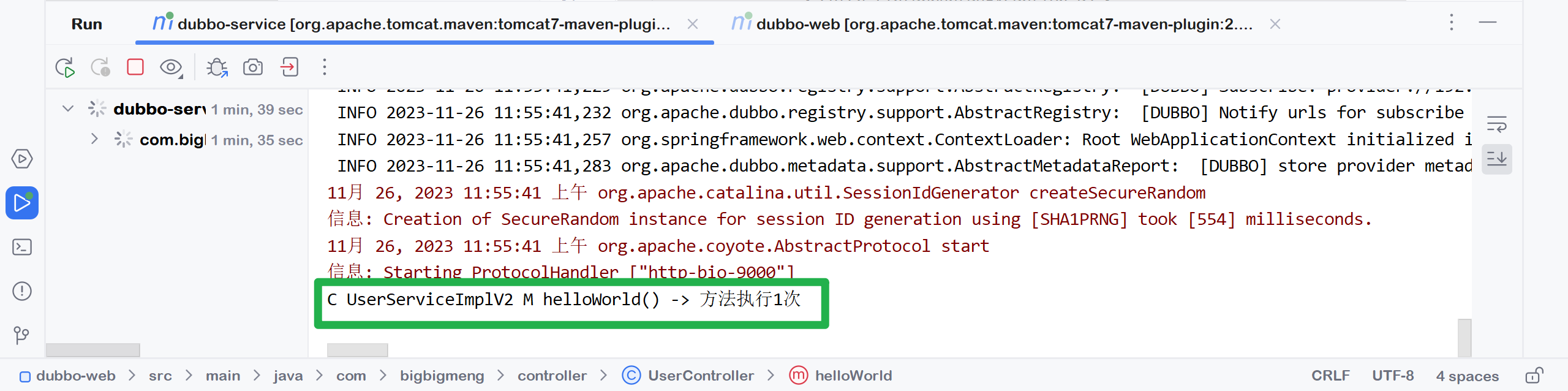
public String helloWorld() {
System.out.println("C UserServiceImpl M helloWorld() -> 方法执行");
try {
// 🎯 模拟超时的场景 程序睡5秒
Thread.sleep(5000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
return "hello BigBigMeng~ Welcome to use Dubbo!";
}
...
}
再配置web模块的Controller类 模式秒数打印 期望打印到第三秒的时候程序报错
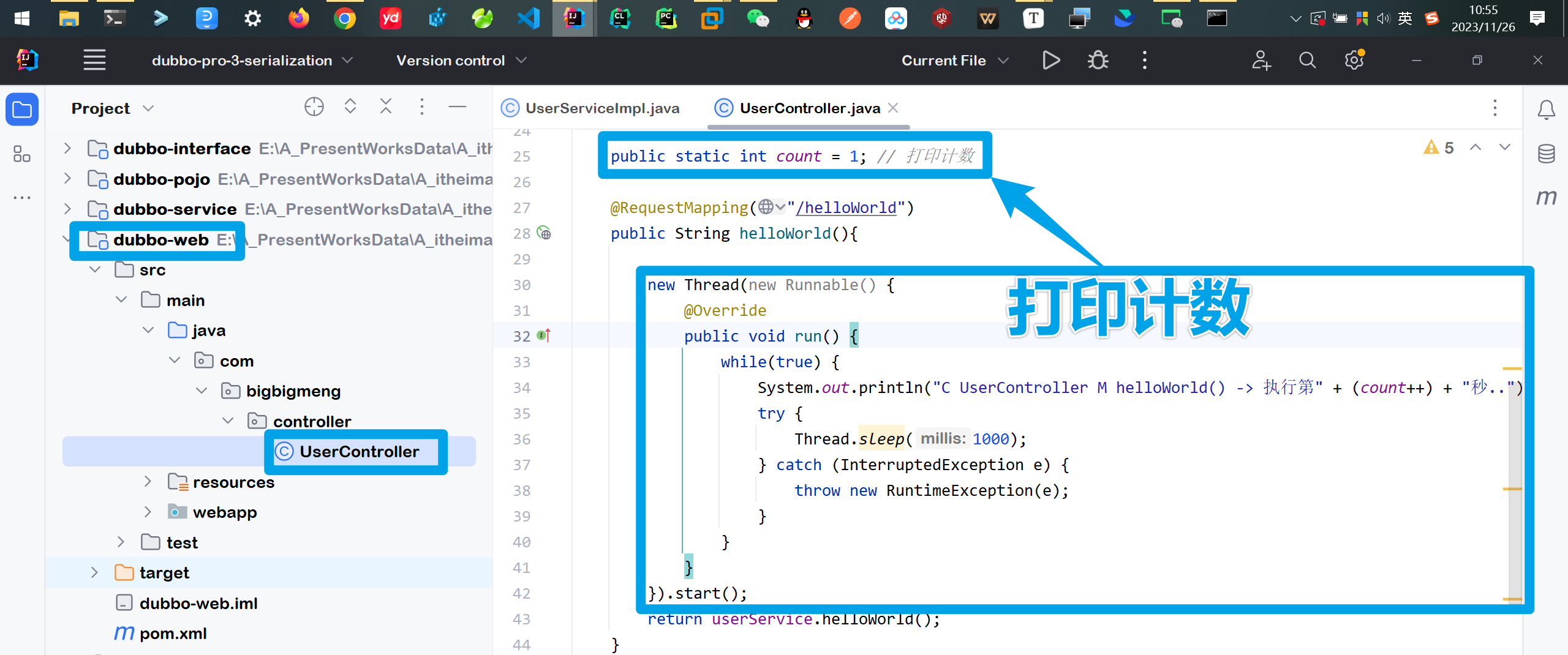
⚡测试执行1
页面预期报错
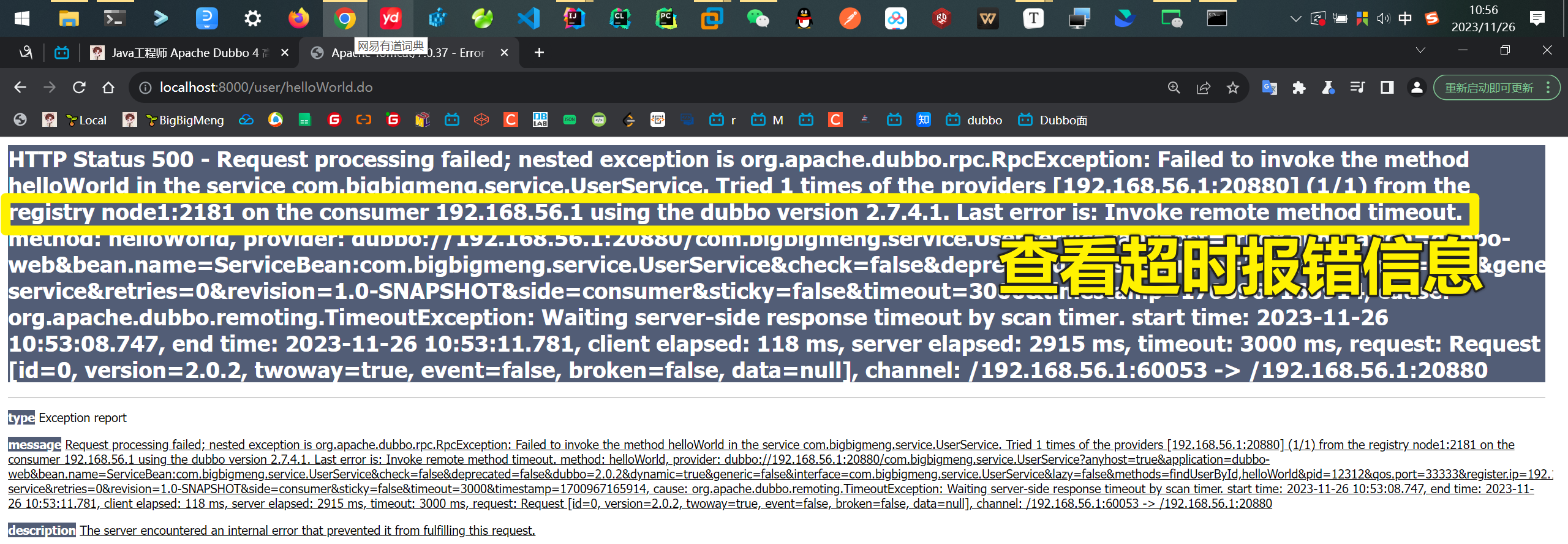
后端预期报错
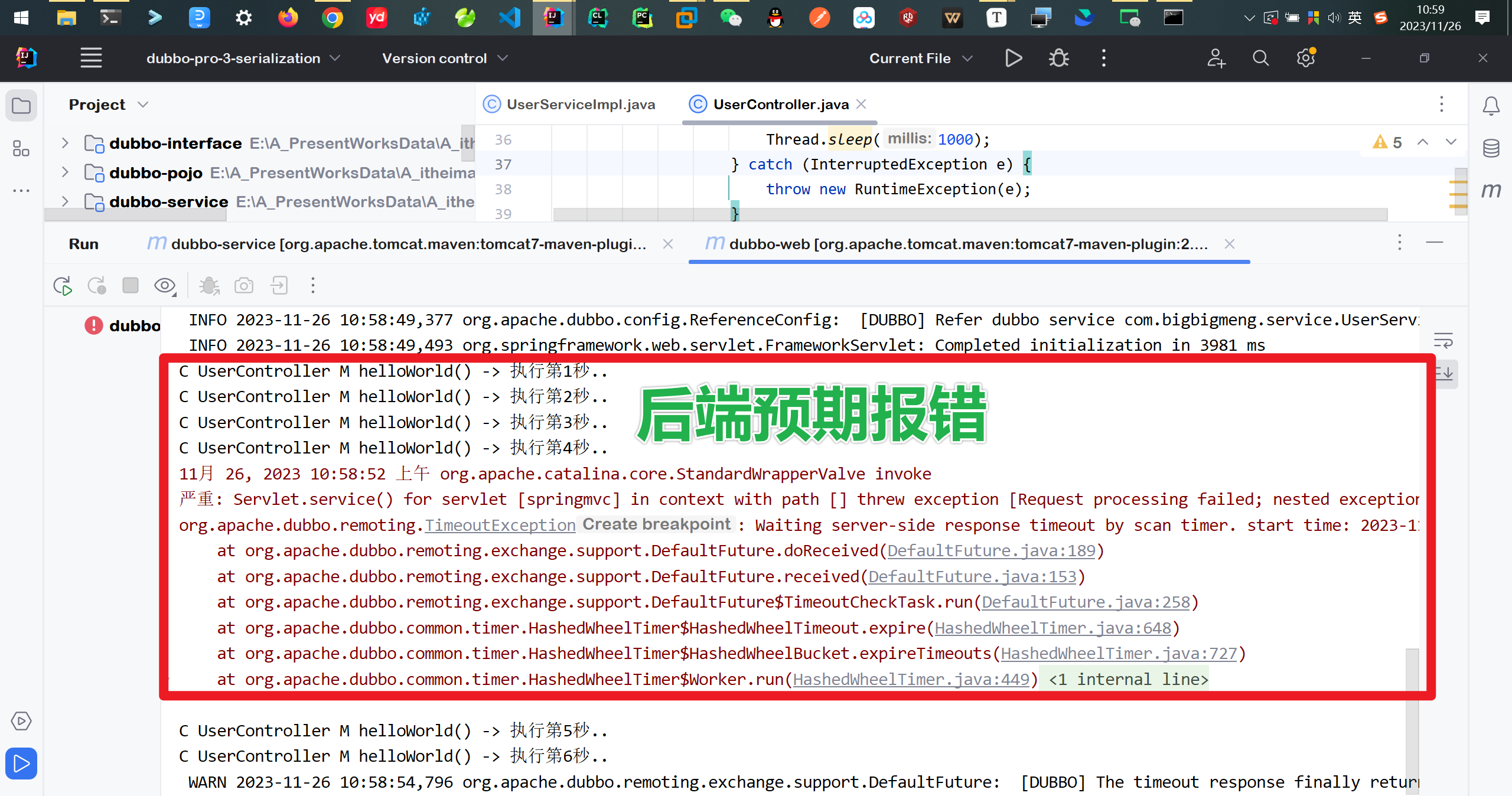
演示@Reference注解上进行配置超时
在@Service注解已经配置了
@Service(timeout = 3000, retries = 0)的情况下 将web模块的用于远程注入的@Reference注解配置为1秒超时@Reference(timeout = 1000)下面运行查看效果
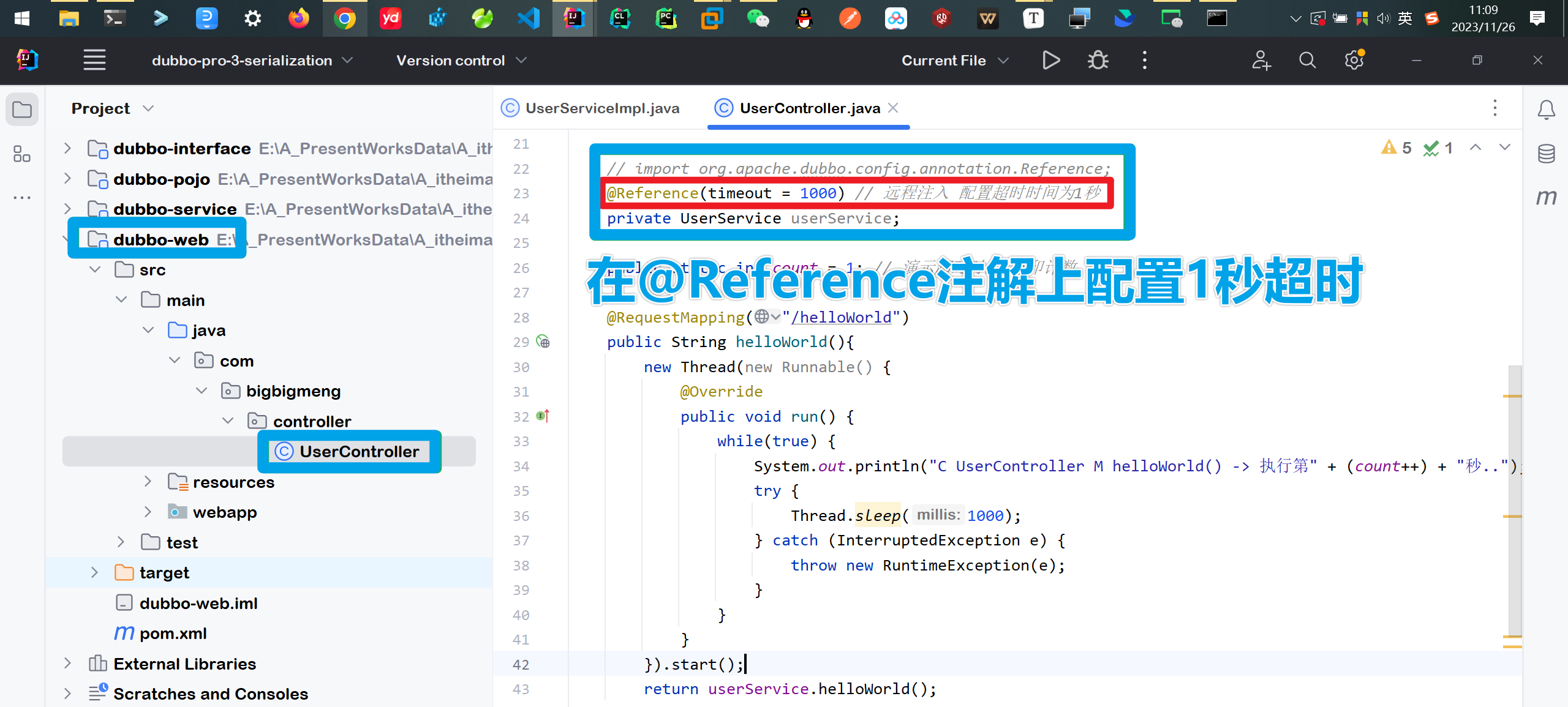
⚡测试执行2
下面运行查看效果 看看是
@Service(timeout = 3000, retries = 0)生效还是@Reference(timeout = 1000)生效

查看后端结果 1秒后就有了预期的报错信息
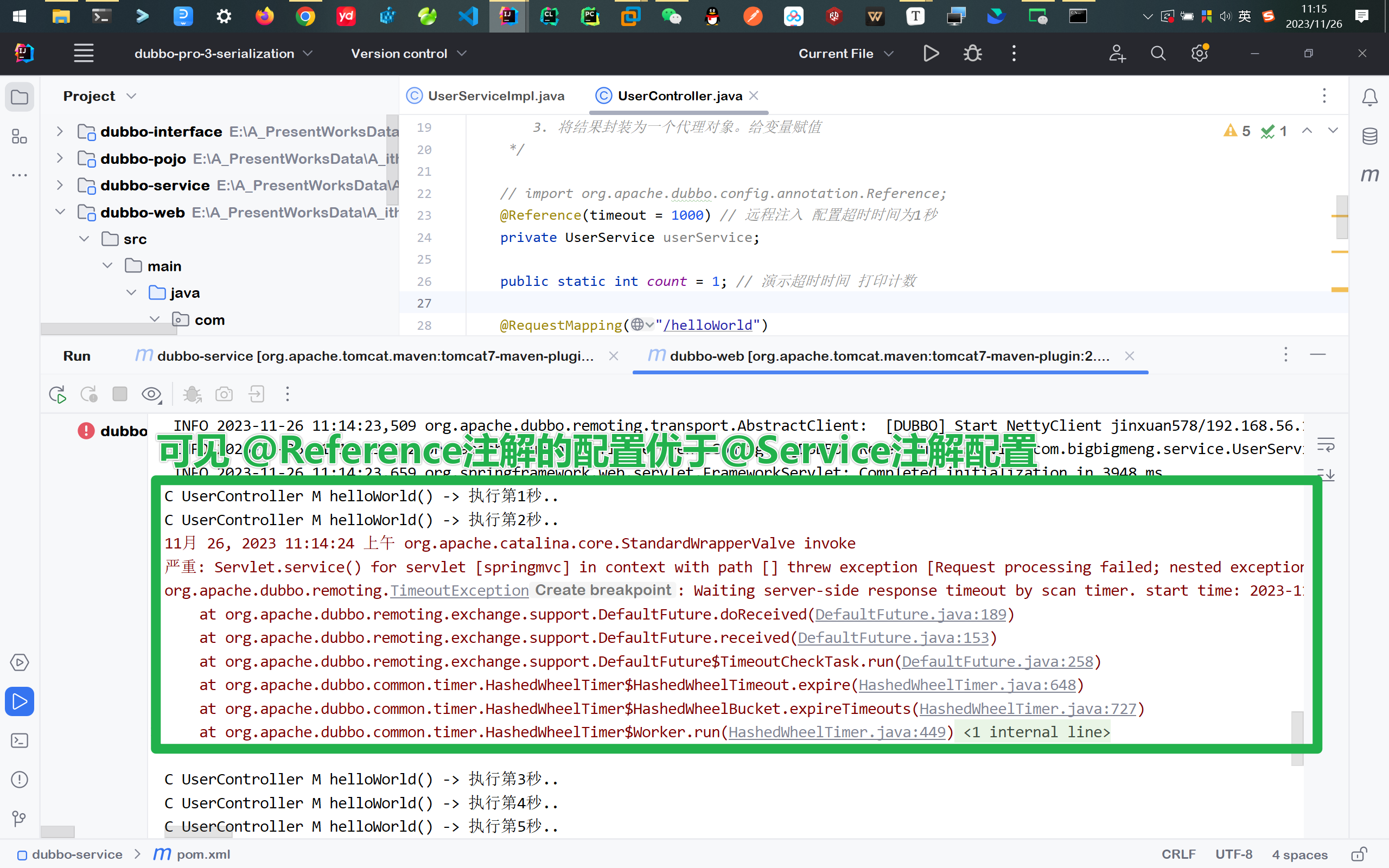
演示@Service注解上进行配置重试
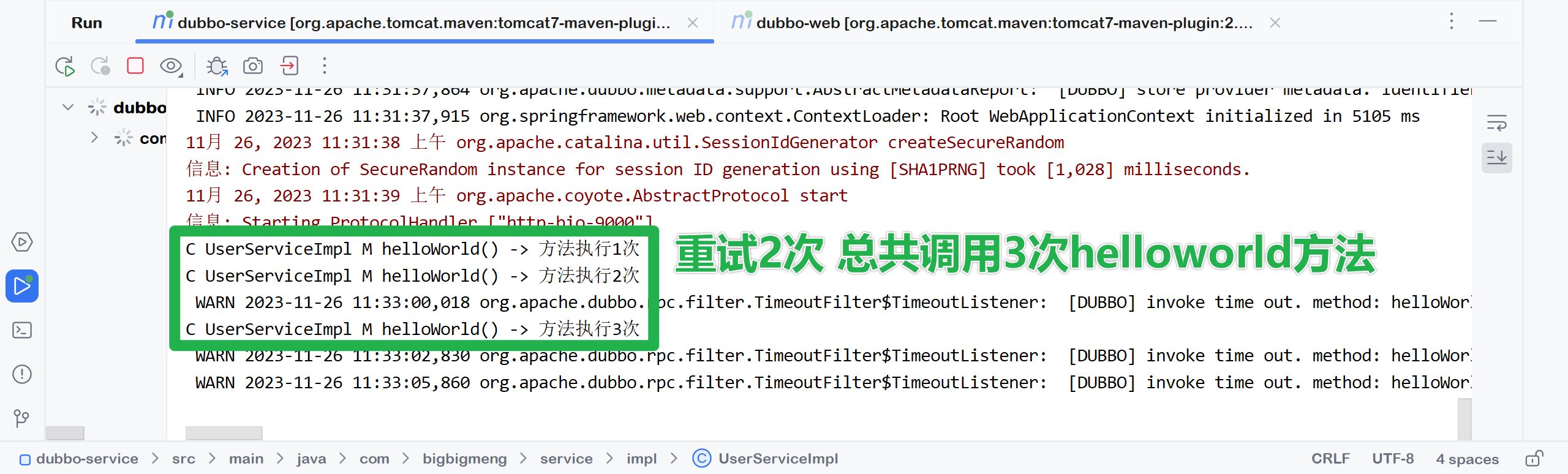
retries默认的重试次数配置就是2次 🎯设置休眠时间大于超时时间
@Service(timeout = 3000, retries = 2) // retries默认的重试次数配置就是2次
public class UserServiceImpl implements UserService {
int count = 1;
public String helloWorld() {
System.out.println("C UserServiceImpl M helloWorld() -> 方法执行" + count++ + "次");
try {
Thread.sleep(5000); // 🎯设置休眠时间大于超时时间
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
return "hello BigBigMeng~ Welcome to use Dubbo!";
}
...
}
⚡测试执行3 验证重试次数
🎄Dubbo高级特性 -> 多版本
🍭概述
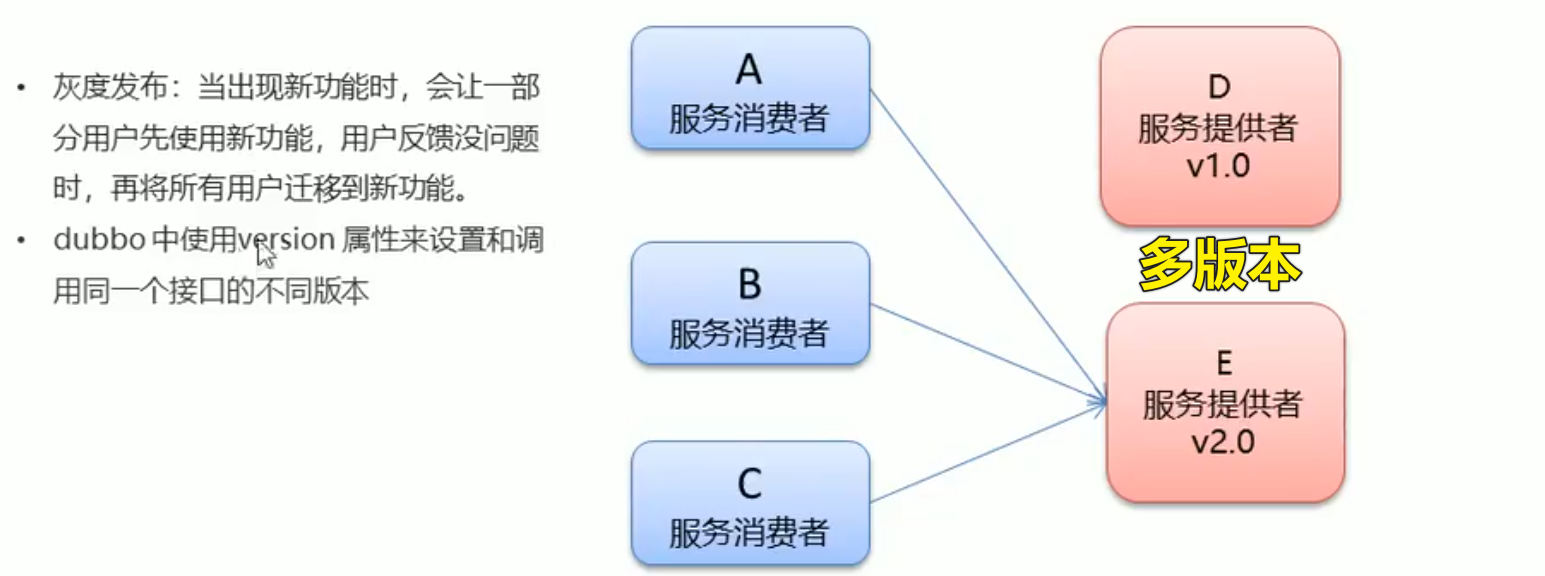
在真实的开发场景中 当出现新的功能时 会先让一部分用户先使用新的功能 用户反馈没有问题的时候 再将所有用户的迁移到新的版本 -> 先让一部分用户先使用新的功能,称为
灰度发布
灰度发布是一种渐进式的软件部署策略,也被称为渐进式交付或部分部署。它的核心思想是将新的软件版本在生产环境中逐步释放给一小部分用户,然后逐步扩大覆盖范围,以确保新版本在整个用户群体中的稳定性和可靠性Dubbo中使用
version属性来设置和调用同一个接口的不同版本
🍭多版本实操
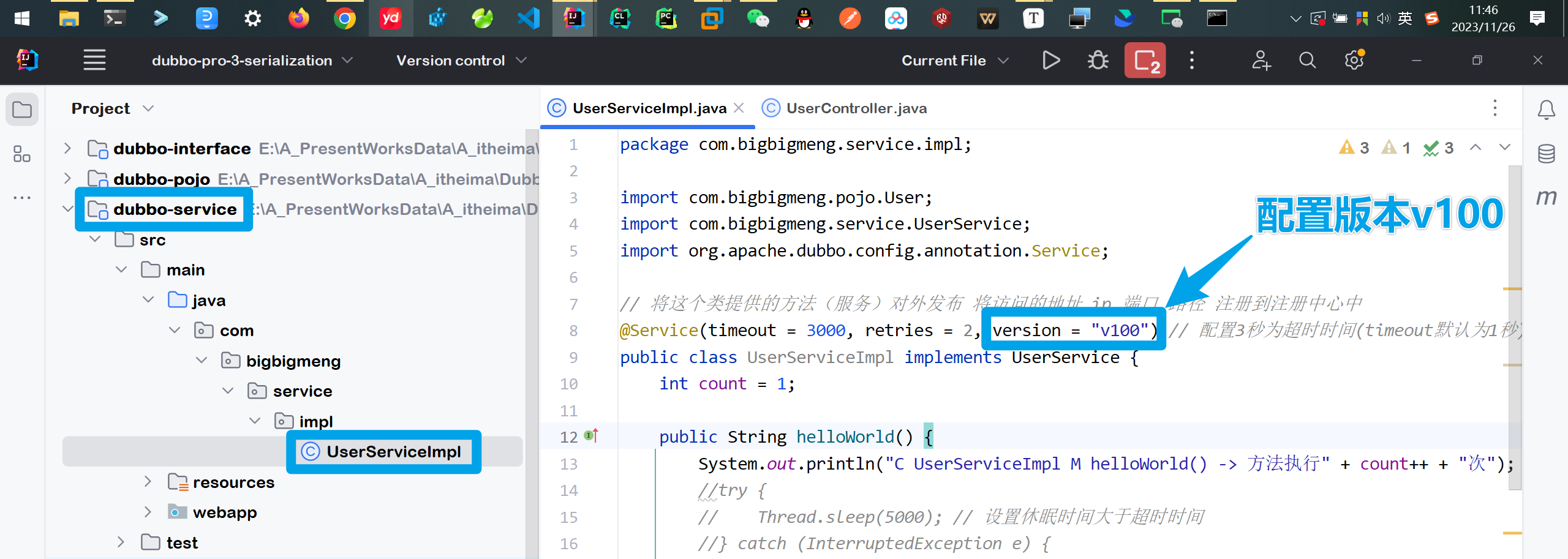
给第一个
UserServiceImpl类配置版本为v100
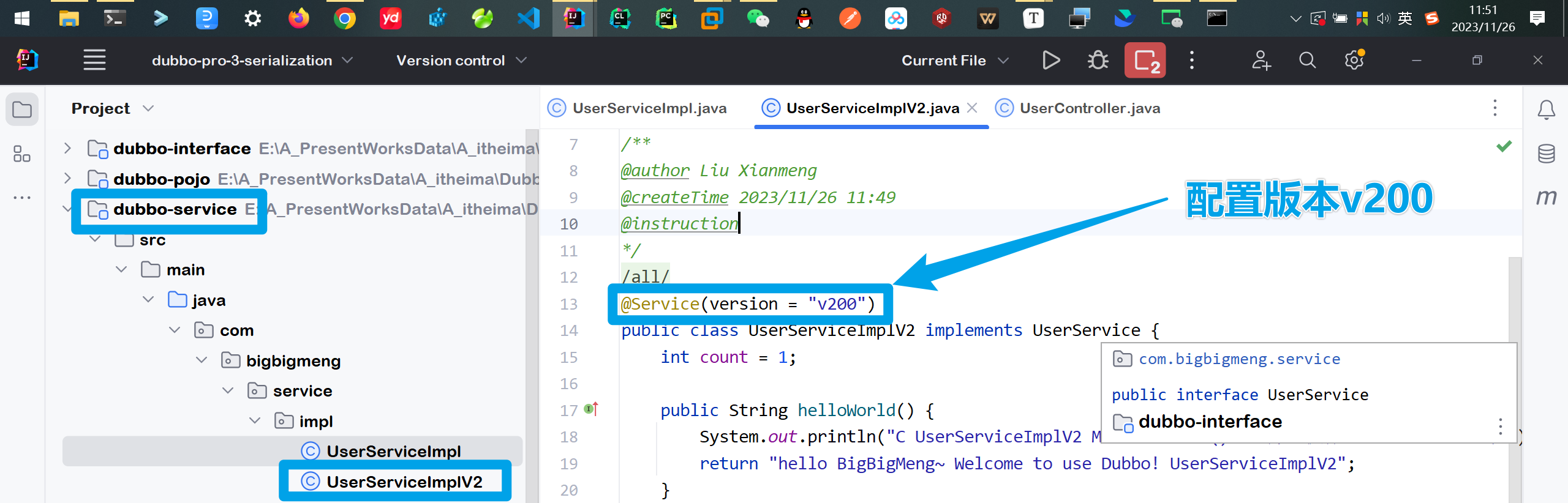
创建第二个
UserServiceImplV2类配置版本为v200
package com.bigbigmeng.service.impl;
/**
@author Liu Xianmeng
@createTime 2023/11/26 11:49
@instruction
*/
@SuppressWarnings({"all"})
@Service(version = "v200")
public class UserServiceImplV2 implements UserService {
int count = 1;
public String helloWorld() {
System.out.println("C UserServiceImplV2 M helloWorld() -> 方法执行" + count++ + "次");
return "hello BigBigMeng~ Welcome to use Dubbo! UserServiceImplV2";
}
public User findUserById(int id) {
System.out.println("C UserServiceImplV2 M findUserById() -> 方法执行");
//查询User对象
User user = new User(1,"zhangsan","123");
return user;
}
}
@Reference注解指定调用的服务版本
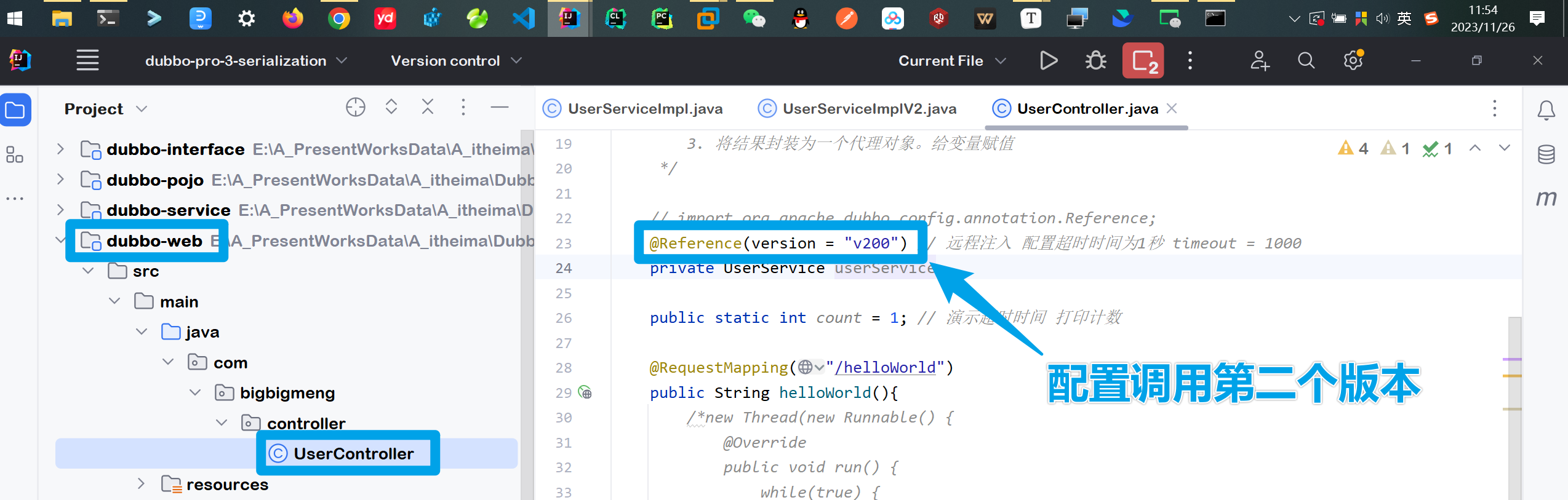
⚡测试执行

🎄Dubbo高级特性 -> 负载均衡
🍭概述
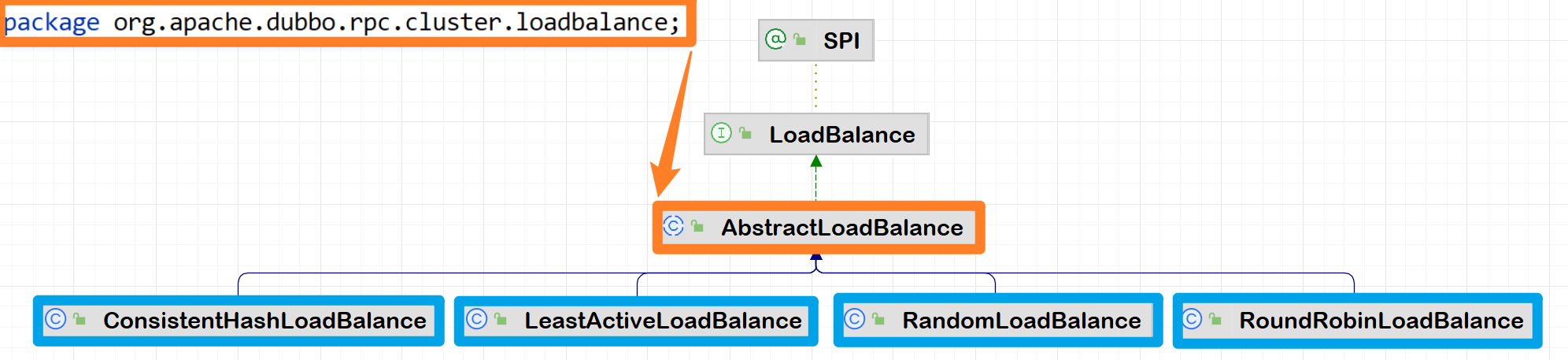
使用
负载均衡的前提是搭建好集群也就是说单点服务只有负载而不存在均衡负载均衡的四种策略:(1)随机(2)按照权重轮询(3)最少活跃调用次数(将新的请求发送到当前
活动连接数最少的服务器上)(4)根据哈希值分配负载

四种负载均衡对应四个实现类
🍭使用方式
将负载均衡的实现类中的属性
NAME字段值 填充到@Reference注解的 比如下面的🎯NAME = “consistenthash”
public class ConsistentHashLoadBalance extends AbstractLoadBalance {
public static final String 🎯NAME = "consistenthash";
public static final String HASH_NODES = "hash.nodes";
public static final String HASH_ARGUMENTS = "hash.arguments";
private final ConcurrentMap<String, ConsistentHashSelector<?>> selectors = new ConcurrentHashMap();
...
}
// import org.apache.dubbo.config.annotation.Reference;
@Reference(version = "v100", 🎯loadbalance = "consistenthash")
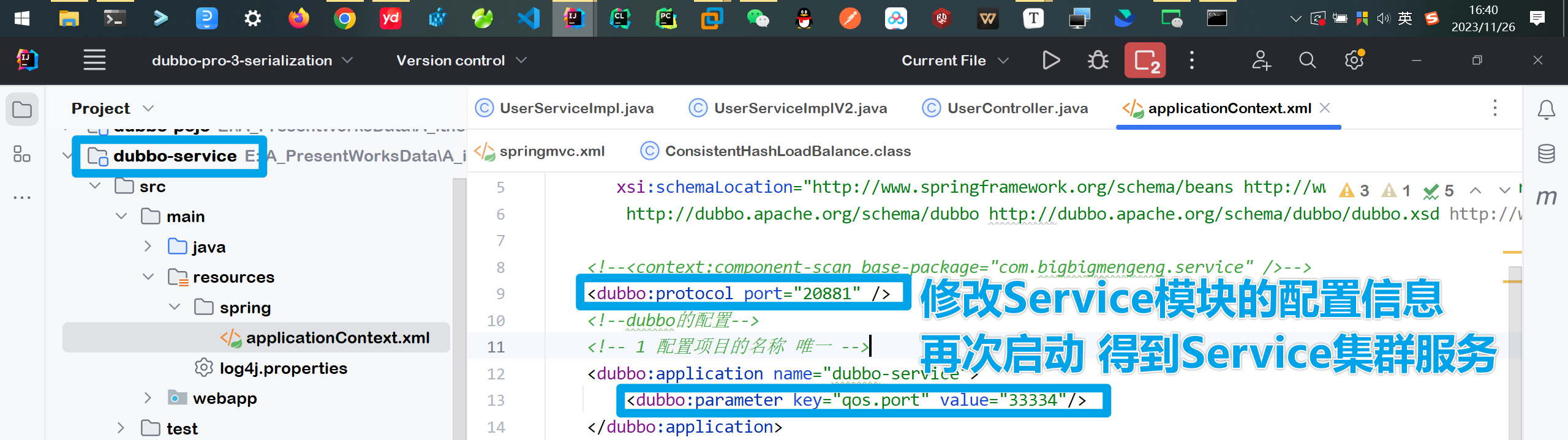
配置完成后 启动Service集群进行测试
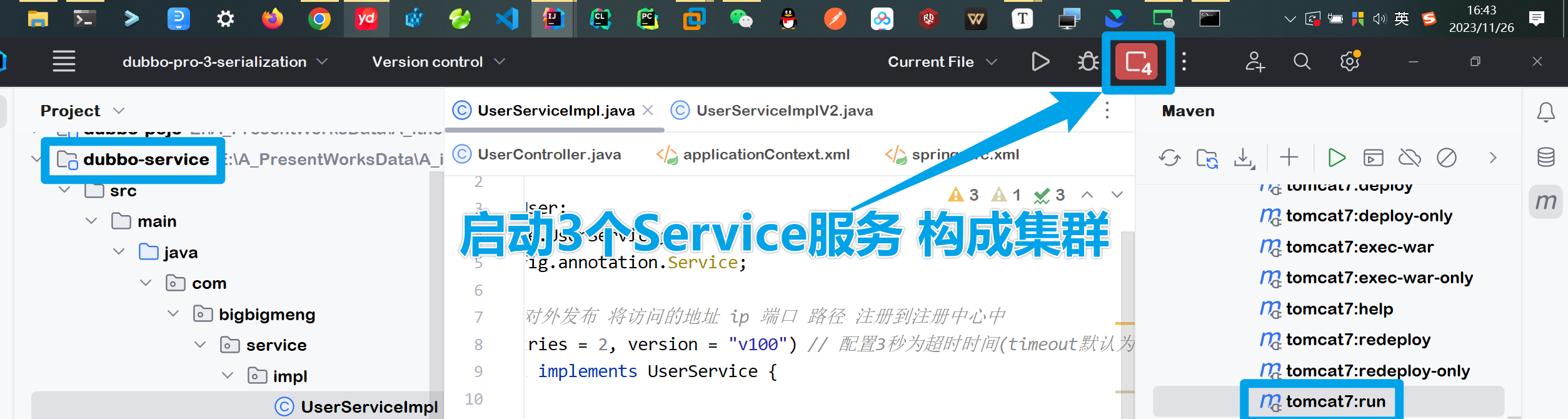

⚡执行测试



🎄Dubbo高级特性 -> 容错机制
🍭概述
搭建并使用集群的时候 默认情况下使用的集群
容错模式是Failover
其他容错模式的使用可见Dubbo的官网
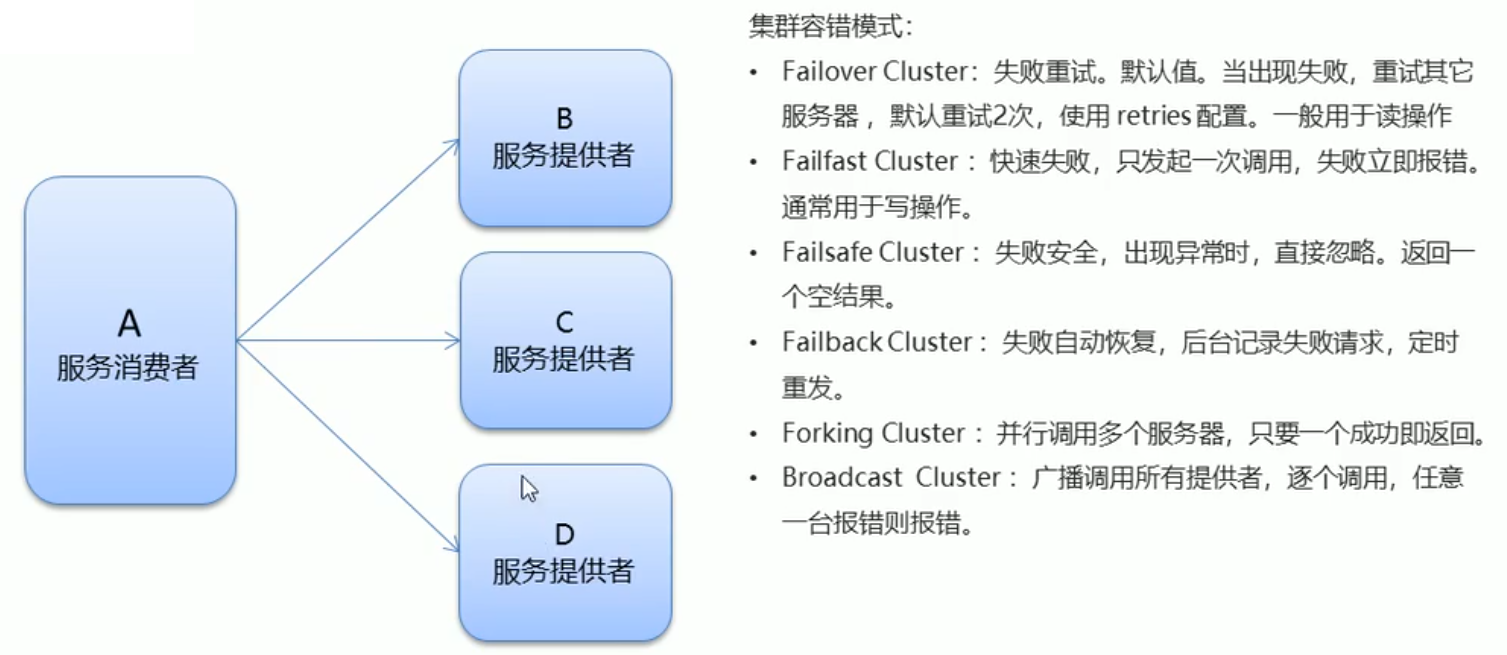
🍭实操使用
在@Reference注解中配置属性
cluster的值为failover使用失败重试的集群容错模式@Reference(version = “v100”, loadbalance = “random”,
cluster = "failover")
❗注意 上面的服务结点启动点要修改配置文件的端口(包括Dubbo相关的端口和Tomcat的端口)否则服务启动会报错(端口已经被占用)
⚡执行测试
首先 随机调用了结点1提供的服务
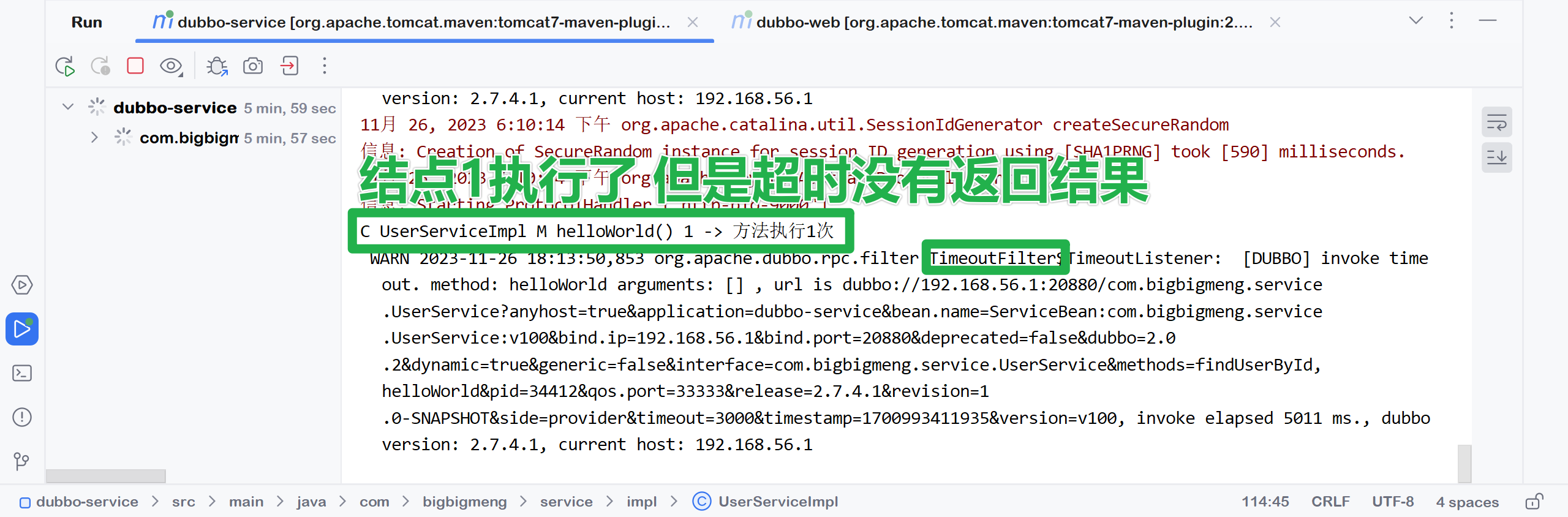
结点1超时后 又随机调用了结点3提供的服务 执行成功并返回结果

由此 我们就能体会到Dubbo提供的容错机制的作用了 它能够
提升服务的可用性
🎄Dubbo高级特性 -> 服务降级
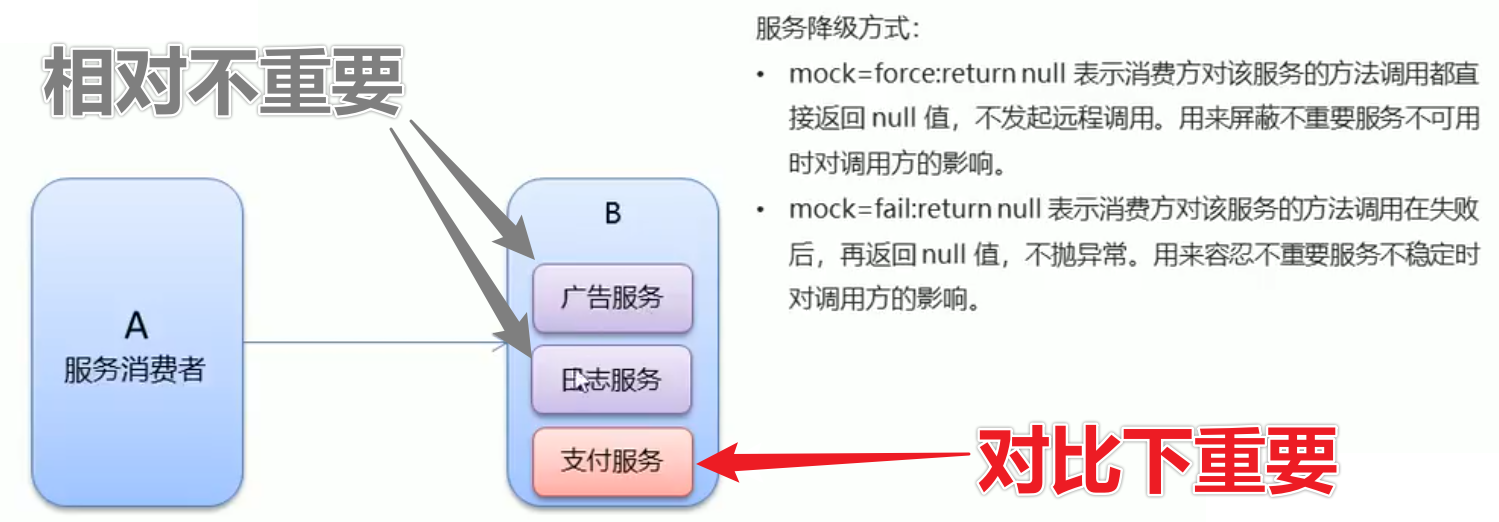
🍭概述
降级是指在系统负载过高或部分服务不可用时,临时屏蔽掉一些非核心或消耗较大的功能,以保证系统的基本功能仍能使用。通过适时地降低对资源的消耗,系统可以在负载下降后恢复正常运行,避免系统整体崩溃。
🍭实操使用
@Reference(mock = "force:return null")
private UserService userService; // 强制UserService服务返回结果为null
⚡执行测试
重启web服务消费模块 浏览器访问

参考链接 https://www.bilibili.com/video/BV1MP4y1W7wS?p=20&vd_source=d97bea5bef5878b5204403b829bd6218