
初探
持久层框架 诞生前
在简化数据库操作的持久层框架出现之前,使用Java操作数据库(如MySQL)通常需要以下步骤:
- 加载数据库驱动程序:使用Class.forName()方法加载MySQL数据库的JDBC驱动程序。
- 建立数据库连接:使用DriverManager.getConnection()方法建立与数据库的连接,并获取Connection对象。
- 创建和执行SQL语句:通过Connection对象创建Statement或PreparedStatement对象,然后执行SQL查询或更新操作。
- 处理结果集:如果是查询操作,需要对获得的ResultSet进行遍历并处理结果。
- 关闭连接:在操作完成后需要关闭ResultSet、Statement和Connection对象。
/*
* Java代码示例如下
*/
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class JDBCExample {
public static void main(String[] args) {
Connection connection = null;
Statement statement = null;
ResultSet resultSet = null;
// 加载MySQL数据库驱动程序
try {
Class.forName("com.mysql.cj.jdbc.Driver");
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
try {
// 建立数据库连接
connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/mydatabase", "username", "password");
// 创建和执行SQL语句
statement = connection.createStatement();
resultSet = statement.executeQuery("SELECT * FROM mytable");
// 处理结果集
while (resultSet.next()) {
// 处理每一行数据
int id = resultSet.getInt("id");
String name = resultSet.getString("name");
// 其他操作...
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
// 关闭连接
try {
if (resultSet != null) {
resultSet.close();
}
if (statement != null) {
statement.close();
}
if (connection != null) {
connection.close();
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
持久层框架 的优点
- 简化SQL编写:MyBatis使用XML或注解来配置SQL语句,使得SQL语句的编写更加简单和直观。
- 减少样板代码:MyBatis封装了数据库连接、资源管理和结果集映射等繁琐的操作,简化了开发人员的工作。
- 提高可维护性:将SQL语句和Java代码分离,使得代码更易读、易维护,并且便于修改和优化SQL语句。
- 支持映射:MyBatis支持将数据库中的记录映射为Java对象,减少了手动的数据转换工作。
- 提供高级特性:MyBatis提供了诸如延迟加载、缓存等高级特性,帮助提升系统的性能和扩展性。
SQL代码在XML文件中:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!-- 20240331 namespace映射接口文件 -->
<mapper namespace="com.bigbigmeng.aurora_sync.infra.dal.dao.LastLoginRecordDao">
<!-- 20240331 resultMap映射要操作的表 -->
<resultMap id="resultMap" type="com.bigbigmeng.aurora_sync.infra.dal.DO.LastLoginRecordDO">
<id column="id" property="id" jdbcType="BIGINT"/>
<result column="user_id" property="userId" jdbcType="VARCHAR"/>
<result column="login_time" property="lastLoginTime" jdbcType="TIMESTAMP"/>
</resultMap>
...
<select id="getOneByPhoneNumber" resultType="com.bigbigmeng.aurora_sync.infra.dal.DO.LastLoginRecordDO">
select *
from `user_login_record`
where `user_id` = #{phoneNumber,jdbcType=VARCHAR}
</select>
...
</mapper>
数据库操作接口在接口文件:
/**
@Author bigbigmeng
@CreateTime 2024/3/31 16:42
*/
@Mapper
public interface LastLoginRecordDao {
LastLoginRecordDO getOneByPhoneNumber(String phoneNumber);
}
使用的时候直接调用接口执行操作:
/**
@Author bigbigmeng
@CreateTime 2024/1/16 18:04
@Instruction 用户信息仓库 注意使用@Repository注解
*/
@Repository
@RequiredArgsConstructor
public class UserRepository {
private final LastLoginRecordDao lastLoginRecordDao;
...
public LastLoginRecordDO getLoginDoByPhoneNumber(String phoneNumber) {
return lastLoginRecordDao.getOneByPhoneNumber(phoneNumber);
}
...
}
使用方法
动态SQL
测试之前建表添加测试数据
-- ----------------------------
-- Table structure for `monster`
-- ----------------------------
DROP TABLE IF EXISTS `monster`;
CREATE TABLE `monster` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`age` int(11) NOT NULL,
`birthday` date DEFAULT NULL,
`email` varchar(255) NOT NULL,
`gender` tinyint(4) NOT NULL,
`name` varchar(255) NOT NULL,
`salary` double NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=22 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of monster
-- ----------------------------
INSERT INTO `monster` VALUES ('1', '23', '2022-07-15', '2751187368@qq.com', '1', 'jin', '200018000');
INSERT INTO `monster` VALUES ('3', '11', '2022-07-15', 'jack1@qq.com', '1', '马云-1', '7000');
INSERT INTO `monster` VALUES ('4', '12', '2022-07-15', 'jack@qq.com', '1', '马云-2', '688888888');
INSERT INTO `monster` VALUES ('6', '14', '2022-07-15', 'jack@qq.com', '1', 'zhangsan', '10000');
INSERT INTO `monster` VALUES ('8', '10', '2022-07-15', 'jack@qq.com', '1', 'jin_008', '6000');
INSERT INTO `monster` VALUES ('9', '11', '2022-07-15', 'jack@qq.com', '1', 'jin_009', '7000');
INSERT INTO `monster` VALUES ('10', '10', '2022-07-15', 'jack@qq.com', '1', '马化腾-0', '6000');
INSERT INTO `monster` VALUES ('18', '20', '2022-07-19', 'jack@qq.com', '1', 'Jin_008', '999');
INSERT INTO `monster` VALUES ('19', '21', '2022-07-19', 'jack@qq.com', '1', 'Jin_1', '7000');
INSERT INTO `monster` VALUES ('21', '100', '1999-12-01', 'insert@qq.com', '2', 'Devin', '666');
if
<!--
【查询age大于10的所有妖怪 如果程序员输入的age不大于0 则输出所有的妖怪】
(1) MyBatis会自动把第一个if中的‘AND’去除'
(2) 对于WHERE标签和if标签的混合使用 后面会给出演示
(3) 为什么一定要有'WHERE 1 = 1' 多余吗? 不多余 因为要拼接后面的'AND age > #{age}'等条件
-->
<select id="findMonsterByAge" resultType="Monster" parameterType="Integer">
SELECT * FROM `monster` WHERE 1 = 1
<if test="age >= 0">
AND age > #{age}
</if>
</select>

where
XML SQL
<!--
(1) 指定id > #{id}条件,
(2) 指定name = #{name}
(3) where + if : WHERE `id` > #{id} AND `name` = #{name}
(4) 如果我们入参是对象,test表达式中, 直接使用对象的属性名即可
(5) where标签,会在组织动态sql时,加上where
(6) mybatis底层自动的去掉多余的AND
-->
<select id="findMonsterByIdAndName" parameterType="Monster" resultType="Monster">
SELECT * FROM `monster`
<where>
<if test="id >= 0">
AND `id` > #{id}
</if>
<if test="name != null and name != ''">
AND `name` = #{name}
</if>
</where>
</select>
测试代码
@Test
public void findMonsterByIdAndName() {
Monster monster = new Monster();
monster.setId(1);
monster.setName("马云-1");
List<Monster> monsters = monsterMapper.findMonsterByIdAndName(monster);
for (Monster m : monsters) {
System.out.println("m--" + m);
}
if (sqlSession != null) {
sqlSession.close();
}
System.out.println("操作成功~");
}
运行结果

choose-when-otherwise
XML SQL
<!--
【条件优先级查询】
(1) 如果给的name不为空 就按名字查询妖怪
(2) 如果指定的id > 0 就按id来查询妖怪
(3) 如果前面两个条件都不满足 就默认查询salary > 100的
(4) 使用mybatis 提供choose-when-otherwise 最终只会有一个条件生效
-->
<select id="findMonsterByIdOrName_choose" parameterType="map" resultType="Monster">
SELECT * FROM `monster`
<choose>
<when test="name != null and name != ''">
WHERE `name` like '%${name}%'
</when>
<when test="id > 0">
WHERE `id` > #{id}
</when>
<otherwise>
WHERE `salary` > 100
</otherwise>
</choose>
</select>
【测试代码1】 id和name条件都不存在(满足)
@Test
public void findMonsterByIdOrName_choose() {
Map<String, Object> map = new HashMap<>();
map.put("id", -1);
List<Monster> monsters = monsterMapper.findMonsterByIdOrName_choose(map);
}
【运行结果1】
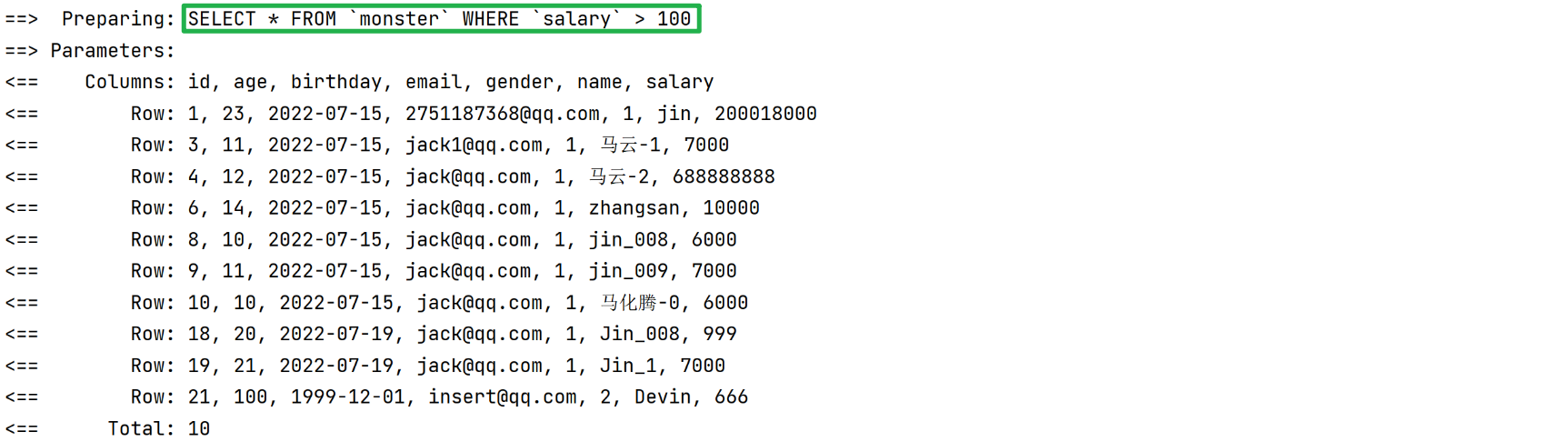
【测试代码2】name条件存在且满足
@Test
public void findMonsterByIdOrName_choose() {
Map<String, Object> map = new HashMap<>();
map.put("id", -1);
map.put("name", "马");
List<Monster> monsters = monsterMapper.findMonsterByIdOrName_choose(map);
...
}
【运行结果2】
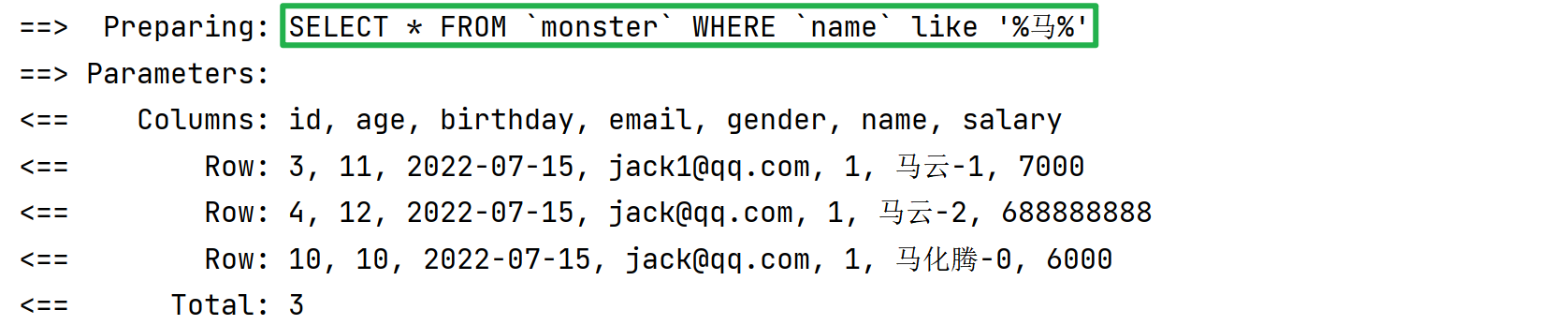
IN
XML SQL
<!--
【map入参中应当有 ids -> [10,12,14]】
1. 判断ids是否为空 如果ids不为空 则使用foreach标签进行遍历
2. collection="ids" 对应你的入参map的 key -> ids
3. item="id" 在遍历ids集合时,每次取出的值,对应的变量id
4. open="(" 对应的就是sql (10,12,14) 的'('
5. separator="," 遍历出来的多个值的 分隔符号
6. close=")" 对应的就是sql (10,12,14) 的最后')'
7. #{id} 对应的就是 item="id"
-->
<select id="findMonsterById_forEach" parameterType="map" resultType="Monster">
SELECT * FROM `monster`
<if test="ids != null and ids !=''">
<where>
id IN
<foreach collection="ids" item="id" open="(" separator="," close=")">
#{id}
</foreach>
</where>
</if>
</select>
测试代码
@Test
public void findMonsterById_forEach() {
Map<String, Object> map = new HashMap<>();
map.put("ids", Arrays.asList(10, 12, 14));
List<Monster> monsters = monsterMapper.findMonsterById_forEach(map);
...
}
运行结果

trim
XML SQL
<!--
1. 按名字和年龄 查询妖怪,如果sql语句开头有 and | or 就替换成 where
2. 如果要实现这个功能,其实使用where标签 [加入where 同时会去掉多余的and]
3. trim prefix="WHERE" prefixOverrides="and|or" 若子句的开头为 “AND” 或 “OR” 就去除
【trim标签有以下属性】:
(1) prefix:指定在开始位置需要添加的字符串
(2) suffix:指定在结束位置需要添加的字符串
(3) prefixOverrides and suffixOverrides:指定需要移除的开头或结尾的特定字符(可指定多个)
-->
<select id="findMonsterByName_Trim" parameterType="map" resultType="Monster">
SELECT * FROM `monster`
<!-- 当trim中的所有条件都不成立的情况下 只会生成最开始的部分:SELECT * FROM `monster` -->
<trim prefix="WHERE" prefixOverrides="and|or">
<if test="name != null and name != ''">
AND `name` = #{name}
</if>
<if test="age != null and age != ''">
AND `age` > #{age}
</if>
</trim>
</select>
set
<!--
1. 入参要根据sql语句来配合map
2. set标签会处理多余的
-->
<update id="updateMonster_set" parameterType="map">
UPDATE `monster`
<set>
<if test="age != null and age != ''">
`age` = #{age} ,
</if>
<if test="email != null and email != ''">
`email` = #{email} ,
</if>
<if test="name != null and name != ''">
`name` = #{name} ,
</if>
<if test="birthday != null and birthday != ''">
`birthday` = #{birthday} ,
</if>
<if test="salary != null and salary != ''">
`salary` = #{salary} ,
</if>
<if test="gender != null and gender != ''">
`gender` = #{gender} ,
</if>
</set>
WHERE id = #{id}
</update>
XML映射配置
resultMap && association 1 javaType
User.java
public class User {
private Integer id;
private String name;
// 与Department的关联属性
private Department department;
// Getters and Setters
}
xml
<!-- UserMapper.xml -->
<mapper namespace="com.example.mapper.UserMapper">
<!-- 结果映射定义 -->
<resultMap id="UserResultMap" type="User">
<id column="id" property="id"/>
<result column="name" property="name"/>
<!-- 一对一映射 -->
<association property="department" javaType="Department">
<id column="department_id" property="id"/>
<result column="department_name" property="name"/>
</association>
</resultMap>
<!-- 查询SQL -->
<select id="selectUserById" resultMap="UserResultMap">
select
u.id,
u.name,
d.id as "department_id",
d.name as "department_name"
from user u
join department d on u.department_id = d.id
where u.id = #{id}
</select>
</mapper>
resultMap && association 2 select
现在有两张表


(1) property: 指定要映射关联对象在当前对象中的属性名,本例中是指当前对象有一个属性命名为person,MyBatis将会使用指定的映射器(Mapper)方法加载这个属性的数据。 (2)column: 指明哪个数据库列的值将被作为参数传递给select属性中引用的映射器方法。这里是id,表示当前表的id列的值会被用来调用对应的映射器方法。 (3) select: 指向一个定义在映射器接口中的方法,该方法用来加载期望的关联对象数据。在此例中,它引用了com.hspedu.mapper.PersonMapper.getPersonByCardId方法。这意味着MyBatis将调用PersonMapper中的getPersonByCardId方法,并传入由column指定的列值(即id的值),以便获取到相应的person对象。
<!-- 假设下面的Mapper映射文件属于Card对象 -->
<mapper namespace="com.hspedu.mapper.CardMapper">
<resultMap id="CardResultMap" type="Card">
<id property="id" column="id"/>
<result property="cardNumber" column="card_number"/>
<!-- 关联person对象 -->
<association property="person" column="person_id"
select="com.hspedu.mapper.PersonMapper.getPersonById"/>
</resultMap>
<select id="selectCardById" resultMap="CardResultMap">
SELECT * FROM card WHERE id = #{id}
</select>
</mapper>
<!-- PersonMapper -->
<mapper namespace="com.hspedu.mapper.PersonMapper">
<select id="getPersonById" resultType="Person">
SELECT * FROM person WHERE id = #{id}
</select>
</mapper>
resultMap && collection 3 ofType
<resultMap id="UserResultMap" type="User">
<id property="id" column="id"/>
<result property="name" column="name"/>
<!-- 因为pets属性是集合 因此这里需要是collection标签来处理
1. ofType="Pet" 指定返回的集合中存放的数据类型Pet
2. collection 表示 pets 是一个集合
3. property="pets" 是返回的user对象的属性 pets
4. column="id" -> SELECT * FROM `mybatis_user` WHERE `id` = #{id} 返回的id字段对应的值
-->
<collection property="pets" column="id" ofType="Pet"
select="com.hspedu.mapper.PetMapper.getPetByUserId"/>
</resultMap>