
windows系统操作Kafka
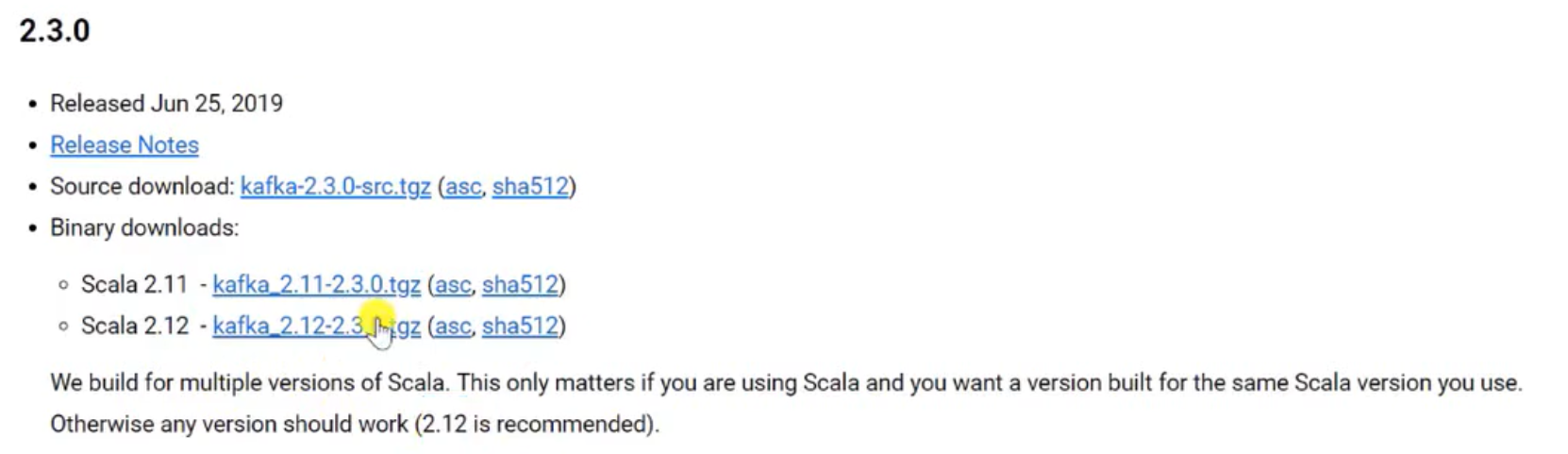
官网下载Kafka安装包
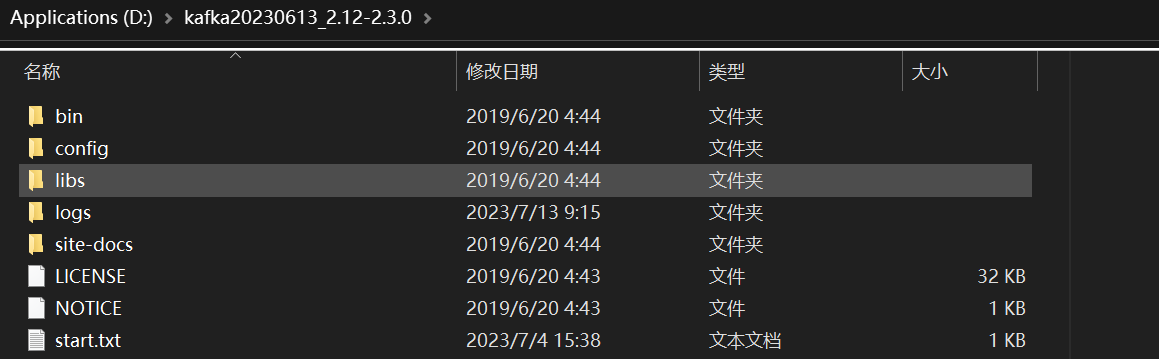
安装Kafka
(1)解压到图中目录

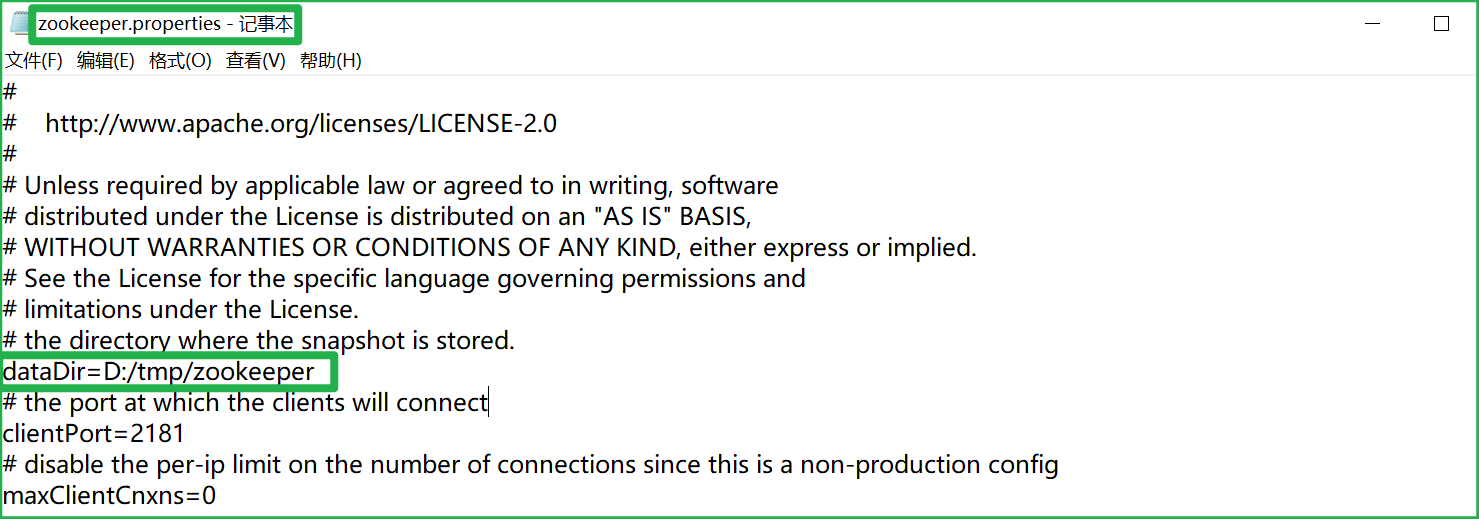
(2)配置zookeeper的数据存放地

(3)配置kafka的日志存放地

启动Kafka
(1)先在Kafka的安装目录下启动zookeeper
./bin/windows/zookeeper-server-start.bat ./config/zookeeper.properties

解决方法?将kafka直接解压缩在E盘启动
(2)将kafka直接解压缩在D盘 启动zookeeper
(2.1)重新安装
(2.2)重新配置目录

(2.3)启动zookeeper 这次启动成功

(3)启动Kafka
./bin/windows/kafka-server-start.bat ./config/server.properties
报错端口被占用

解决办法:将2181的进程kill掉(Linux)
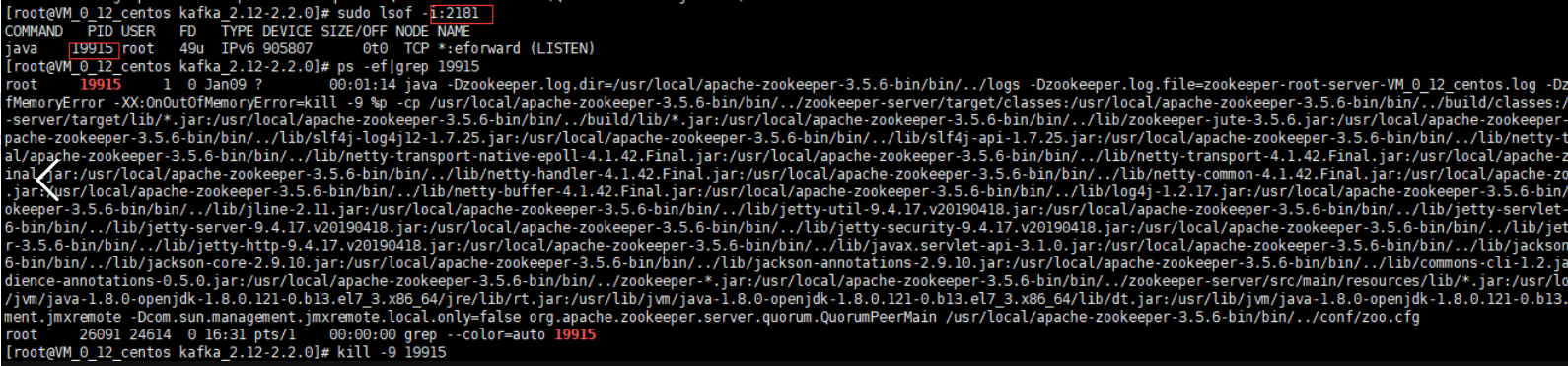
windows如何kill?windows kill进程
netstat -ano
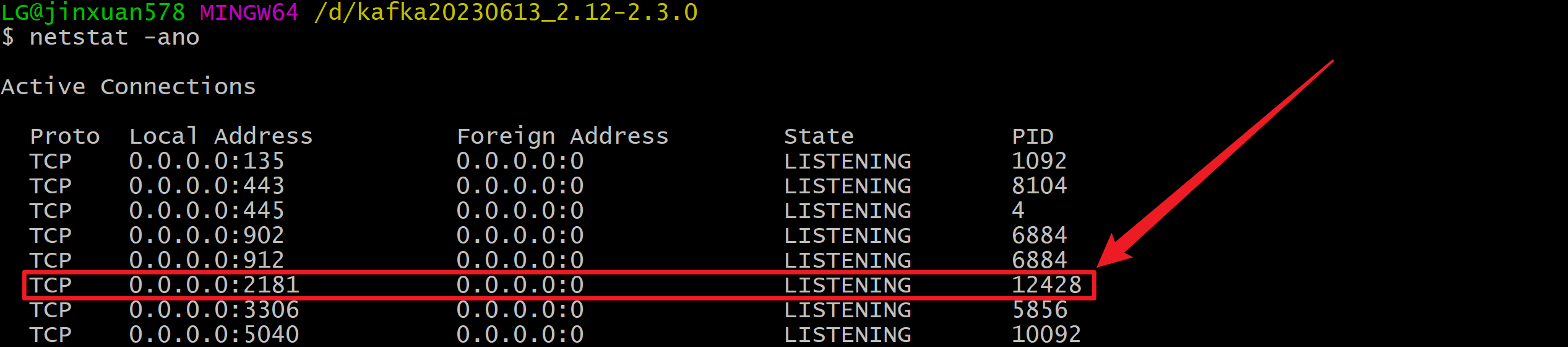
查询对应的服务 tasklist | findstr "12428"

kill这个服务 taskkill -PID 12428 -F

重新启动kafka:./bin/windows/kafka-server-start.bat ./config/server.properties
启动成功

命令行实操
创建主题topic
./bin/windows/kafka-topics.bat --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic test
这行命令是用于Apache Kafka的一个命令行工具,具体是kafka-topics.bat(在Windows环境下)。这个命令的作用是创建一个新的Kafka主题(topic),并设置其相关参数。下面是对这个命令各部分的详细解释:
./bin/windows/kafka-topics.bat:这是Kafka为Windows提供的命令行工具的路径。通过这个脚本,用户可以执行与Kafka主题相关的各种操作。--create:这个参数指示我们要创建一个新的Kafka主题。--bootstrap-server localhost:9092:这个参数指定了Kafka集群的地址。在这里,localhost:9092表示Kafka集群正在本地机器上运行,并且 ** 9092端口。Kafka客户端(包括这个命令行工具)会使用这个地址来连接到Kafka集群。--replication-factor 1:这个参数设置了主题的副本因子(replication factor)。副本因子决定了主题的每个分区(partition)应该有多少个副本。在这个例子中,每个分区只有一个副本。通常,为了提高数据的可靠性和系统的容错性,会设置副本因子大于1。--partitions 1:这个参数设置了主题的分区数。分区是Kafka实现高吞吐量的关键之一,它允许并行读写操作。在这个例子中,主题只有一个分区。--topic test:这个参数指定了要创建的主题的名称,这里是“test”。
这行命令的作用是:在本地运行的Kafka集群上创建一个名为“test”的新主题,该主题有一个分区和一个副本。
在实际生产环境中,通常会设置更高的副本因子和更多的分区,以提高系统的可靠性和吞吐量。

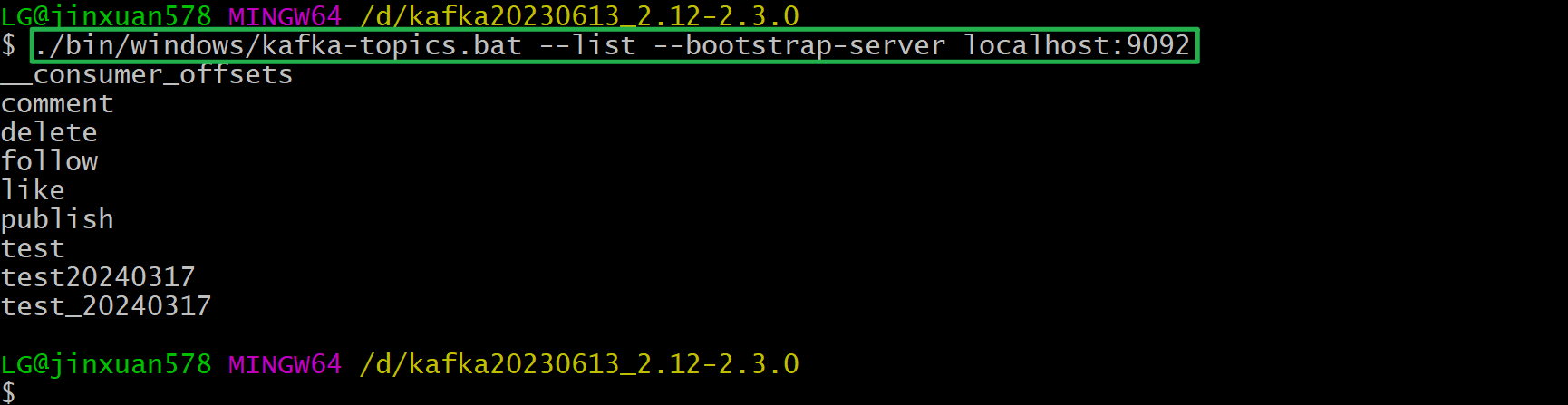
列出所有的topic
./bin/windows/kafka-topics.bat --list --bootstrap-server localhost:9092
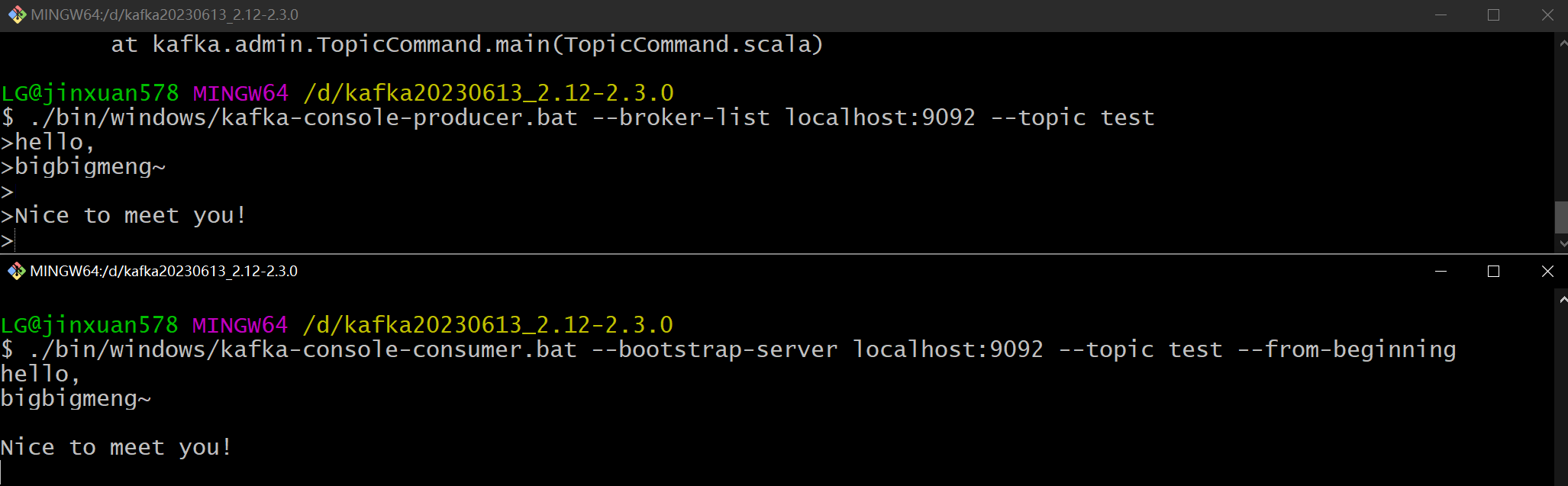
使用终端进行生产
./bin/windows/kafka-console-producer.bat --broker-list localhost:9092 --topic test

使用终端进行消费
./bin/windows/kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test --from-beginning #从头开始读取

上面生产,下面消费
java操作Kakfa
(1)依赖
<!-- 20230613 加上kafka的依赖 -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
(2)配置
spring:
kafka:
bootstrap-servers: localhost:9092
consumer:
group-id: test-consumer-group
enable-auto-commit: true # 是否自动提交偏移量offset->下标索引
auto-commit-interval: 3000 # 自动提交的频率
(3)定义生产者
@Component
public class EventProducer {
@Autowired
private KafkaTemplate kafkaTemplate;
// 处理事件
public void fireEvent(Event event){
// 将事件发布到指定的主题
kafkaTemplate.send(event.getTopic(), JSONObject.toJSONString(event));
System.out.println("C EventProducer M fireEvent(Event event) -> 发出event = " + JSONObject.toJSONString(event));
}
}
(4)定义消费者
@Component
public class EventConsumer {
/**
* 监听评论、点赞、关注三个主题
*/
@KafkaListener(topics = {CommunityConstant.TOPIC_COMMENT,
CommunityConstant.TOPIC_LIKE, CommunityConstant.TOPIC_FOLLOW})
public void handleCommentMessage(ConsumerRecord record) {
if (record == null || record.value() == null) {
logger.error("消息的内容为空!");
return;
}
// 转换成消息对象进行处理
Event event = JSONObject.parseObject(record.value().toString(), Event.class);
if (event == null) {
logger.error("消息格式错误!");
return;
}
// 处理event
...event
}
}
kafka常见术语
- Broker:这是Kafka集群中的一个或多个节点。Kafka的集群架构可以看作是由多个Broker组成,它们一起处理生产者发布的消息,并且向消费者提供服务。每个Broker在Kafka中都有一个唯一的ID。
- Topic:这是一个特定的消息类别,类似于消息队列中的一个队列或者一个数据库的表名。Kafka的每个Topic都分为多个Partition,生产者将数据发布到特定的Topic中,而消费者从Topic中消费数据。物理上,不同Topic的消息是分开存储的;但在逻辑上,一个Topic的消息可以被一个或多个Consumer Group同时消费。
- Producer:也被称为数据的发布者。该角色负责将数据发送到Kafka的Broker上,每条发送的数据都必须有一个特定的Topic,Broker在接收到Producer发送的消息后,会将数据追加到特定Partition的末尾。生产者可以指定数据发送到哪个Partition。
- Consumer:从Broker中读取数据的角色,消费者可以从一个或多个Topic中读取数据。Consumer读取数据时,需要指定特定的Consumer Group。一个Topic的消息可以被一个或多个Consumer Group消费,但是Consumer Group中的Consumer需要竞争消费同一个Topic的数据。
- Partition:Partition是Kafka保证数据顺序性和一致性的单位,同时也是Kafka实现分布式、高并发的手段。Kafka中一个Topic被分为多个Partition,每个Partition只能被一个Consumer Group中的一个Consumer消费。一个Consumer Group可以同时消费多个Partition。Partition的数据是以日志文件的形式保存在硬盘上。
- Offset:这是一个记录数据位置的指标,每消费一条消息,Offset的值就会增加。消费者可以指定Offset的位置开始消费,这意味着消费者可以控制从哪个位置开始读取消息。Kafka通过这种方式保证消息的有序性和一致性。
- Replica(副本):Kafka为了防止数据丢失和故障转移,会为每个Partition在多个Broker上创建Replica(副本),这些Replica中只有一个是Leader,其他的是Follower。当Leader发生故障时,会选出一个新的Leader来处理数据读写操作。
- ZooKeeper:ZooKeeper是Kafka中用于管理集群状态、配置信息的组件。在Kafka集群中,每个Broker启动时都会在ZooKeeper上注册自己的信息,并通过ZooKeeper来获取其他Broker的信息,以便形成一个集群。此外,Kafka也会使用ZooKeeper来记录消费者的偏移量等元数据信息。
假设有一个电商网站,用户在下单时会产生订单数据。这些订单数据需要被实时处理,以便进行后续的分析和统计。
- Broker:电商网站搭建了一个Kafka集群,其中包含多个Broker节点,用于处理订单数据的读写请求。
- Topic:电商网站定义了一个名为“orders”的Topic,用于存储订单数据。
- Producer:电商网站的后端系统作为Producer,将用户下单时产生的订单数据发送到“orders”Topic中。
- Consumer:电商网站的数据分析系统作为Consumer,订阅了“orders”Topic,实时拉取订单数据进行处理。
- Partition:“orders”Topic被分为多个Partition,每个Partition存储一部分订单数据,以实现负载均衡和并行处理。
- Offset:每条订单数据在Partition中都有一个唯一的Offset,Consumer通过追踪Offset来确保能够按顺序处理每条订单数据,并且不会重复处理或遗漏处理。
- Replica:为了保证数据的可靠性和容错性,每个Partition都有多个Replica,其中一个被选举为Leader,负责处理读写请求,其他为Follower,用于备份数据。如果Leader出现故障,ZooKeeper会协调选举一个新的Leader。
- ZooKeeper:Kafka集群中的ZooKeeper服务负责维护集群的状态信息,确保Broker之间的协调一致,以及Partition的Leader选举等操作的正确性。